mapreduce���ģ�ͽ���
ת�ԣ�http://blog.csdn.net/sxf_824/
�κμ���������δ���Ӵ�����ʱ���Ǿ����������ˮ�����£���ңԶ�����أ����ǵ��㳢��ѧϰ��ͨ��ʵ������������������Ժͻ����ԭ����ô������������ôһ���¶���
mapreduce�ֲ�ʽ���ģ����google��2004��������ģ�Ŀ����Ϊ�˽���������ݵĴ���������ͨ��һ��ʱ���Ӧ�ã���mapreduce��̵�ʵ�ֻ�������һ���˽⣬���ܽ����£�ϣ����ΪӦ�ÿ������ṩ�������Ҿ��������ļ�����
�������ݵĴ������Ǿ������Ƚ������ļ����д�ɢ��Ȼ��Դ�ɢ���ÿһ�����ݿ���ֱ��������ս����ݽ���鲢����ν�ֶ���֮Ҳ����һ����������֮���й�����ô�죬�����ݴ�ɢ����̨�����ϣ����й����������Dz��Ǿ�û�취���з����ˣ��������ϸ���ܡ�
?
�����ȿ�һ��hadoop�Ĵ������̡�
?
?
?
?
?
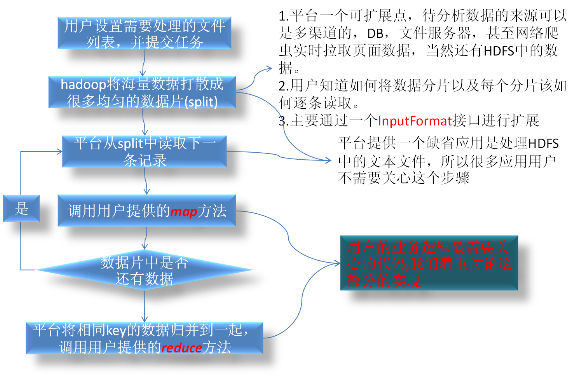
map��������ҪĿ���ǽ������ݽ��зּ𣬷������Լ����ĵ����ݣ���Ϊ��ͬһ��ָ������������ݶ�����һ�����:KEY,?ƽ̨�Ὣ����ͬһ�����KEY�����ݴӸ�̨�������ռ��������е�һ̨������Ȼ������û���reduce�����������ݵ�ͳ�Ʒ�����
����ͨ��һ������ʵ��ѧϰmapreudce����ı�д��
?
1.����ͳ�Ʒ���
����
��������һ�����û�����ҳ����ˮ��־����־��ʽ���£�
�û����ʵ�ҳ��?�û�QQ����?�û�����IP?.....
www.qq.com/sub/..??????21201421????????202.201.22.23
qzone.qq.com/21201421/..???2222222?????????10.201.22.23
?
����Ҫͳ�Ƴ�ÿ������һ����û���(��Ҫȥ��)������������������������������ͨ��IP���Է�����������Ϣ����
?
���û���map������ʲô�����أ�
���ǿ�һ��map�����IJ���
���µ����Ӷ���ͨ��java���뷽ʽʵ�֣���Ȼ��֧�ֺܶ����ԣ���һ��Ҳ����Ҫ���Ǻǣ���
void?map(K1?key,?V1?value,?OutputCollector<K2,?V2>?output,?Reporter?reporter);
?
����ʹ��ϵͳȱʡ�ṩ�Ĵ����ı��ļ���InputFormat��?TextInputFormat�����ǻ�������64M��С����������Ƭ�ģ����ṩ��RecordReader������Key���ļ�������value��һ�е����ݡ�Key��value�������û�Ҳ�����Զ���(��Ȼ��Щ��������η���������,���ֻҪ֪������ô���¶�������)
?
������Ҫ����ÿ������һ����û������취�ܼ���Ҫ�ҵ�ÿ�η��������ĸ��û������ģ��������û�������������ȥ�غ�Ϳ��Եõ��û������������������ʱ��Ͳ��ô����ˣ�(*^__^*)...������û��ϵ���зֲ�ʽ����ƽ̨��
?
1.MapҪ��������,�����Ƿ�����ÿ���¼�е��������Լ��û�QQ���롣
OK!?���������
map(K1?key,?Text?value,?OutputCollector<K2,?V2>?output,?Reporter?reporter)
{
String?lineValue?=?value.toString();
String[]?values??=?lineValue.split("/t");
//����values[0]�õ�����ǰ��?���� www.qq.com
domain?=?process(values[0]);
?
//���������ͬһ�������µ�������Ҫ�鲢��һ��,�ҵ���һ��������ص��û���Ϣ��QQ���룩��ֻ��Ҫ�������Ϣ����һ����Ƿ�������ܡ�
//������������ɣ���Ҫ������ָ���ͻŶ
key?=?domain+"_UV";
//�õ�QQ����
value?=?values[1];
?
//���ҵ���key->value�Է��������
Output.emit(Key?,Value);
}
2.Reduce������Ҫ��ʲô
void?reduce(Text?key,?Iterator<Text>?values,
??????????????OutputCollector<Text,?Text>?output,?Reporter?reporter)
{
if(?postFix(?key?)?==?"_UV"?)?//�ж��Ƿ����û������ָ����ص�����
��
//values�е����ݾ��ǴӸ�̨�����Ϲ��ܹ�����QQ����
String?uv?=?distinctCount(?values?);
//push�����ս��
Output.emit(key,uv?);
��
}
?
�Dz��Ǻܼ�?�û�������Ҫ��ϵ�ֲ�ʽƽ̨��ηֽ�������ι鲢�����ֻ��Ҫ�����Լ���ҵ���������������Ҳ������ν�Ĺ�ע����롣
�û���map�����д�ԭʼ�����з��������Լ����ĵ�ij������ָ���й��������ݣ���������ݴ����ǩ(�����ǩ�ǹؼ�,��Ҫ������ָ�����ظ�Ŷ����������ƽ̨�Զ����������ǩ����������ݻ��ܵ�һ�����ṩ���û��������û���reduce����),��reduce������ֻ��Ҫ���ۼ���һ������ݽ���ͳ�ƻ����������������...
?
������ķ�����������ֻ������һ��������������ôʵ���أ�����Ϊ��������Ӧ��֪�������дmapreudce�����ˣ��һ����ø���α�����������,ok?��ʼ�ˡ�
?
map(K1?key,?Text?value,?OutputCollector<K2,?V2>?output,?Reporter?reporter)
{
1.����һ����û���
��value�����������QQ����
output.emit(��$(����)_UV",$(QQ����));
2.����һ��ķ�������
output.emit(��$(����)_PV",1);
������û�У������ָ��ĺ��Ҹij�_PV�ˣ����˻���Ϊʲôemit���һ�������dz���"1"������QQ�����أ��������ֻ�������������ֲ���Ҫȥ�أ�����QQ�������������˷����������������ֻҪ����Щ��"1"�������͵õ����ʴ����ˡ�?
?
3.�������ܷ�������
��value�з�����IP����IPӳ�������
Output.emit(?func_IP_to_district��ip��+"_DIS"?,?1?);
��Ϊ��Ҳֻ�Ǽ����������ʴ��������Բ���Ҫemit��QQ����
}
?
void?reduce(Text?key,?Iterator<Text>?values,
??????????????OutputCollector<Text,?Text>?output,?Reporter?reporter)
{
if(?key���"_UV"?)
{
ȥ��values�е�QQ���룬����count
//�����ҵ����������û���������������
output.emit(key,count);
}
if(key���"_PV")
{
pvCount=0;
for?ѭ������values
{
pvCount++;
}
//�����ҵ��������ķ�����������������
output.emit(key,pvCount);
}
if(key���"_DIS")
{
disCount=0;
for?ѭ������values
{
disCount++;
}
//�����ҵ��������ķ�����������������
output.emit(key,disCount);
}
}
?
���������ķ���,��ʵҲ����ʵ���˵�����grouybyͳ�ơ�
Select(?count(*)?,?count(distinct(QQ))?)?from?table?grouy?by?$ȡ����(��ҳurl)
Select?count(*)?from?table?groupby?$ȡ����(IP);
?
��Ȼmapreudce������ʵ�����ݵ�ͳ�Ʋ������������ݷ��������Խ���֧�֣���������ֻ�Ǿٸ����ӡ�
�����ٽ��һ����������ͼ����һ��˵���������⣺
?
?
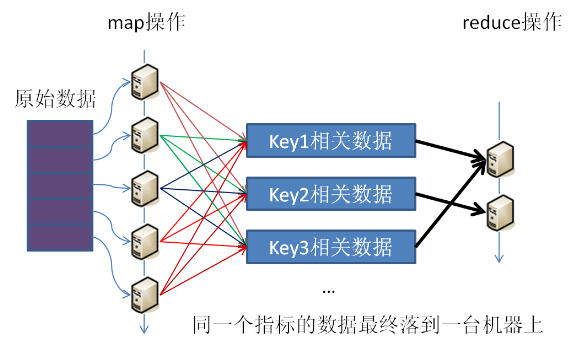
ÿ̨��������������Ƭ����һ������ͬijһָ���й��������ݺܿ��ܷ��䵽��̨�����ϣ�������ͨ��key���Ŧ������һ��ָ������������ݱ����ܵ�һ��,�����û����д�����
?
2.�����ݹ�������
�������ǿ�һ���Ը��ӵ�����,������?
select?sum(A.price),sum(B.count)?form?A?B?where?A.id=B.id?group?by?id;
����A�ĸ�ʽ
id
price
�����ֶ�1
�����ֶ�2
1
2.4
XXX
XXX
2
3.6
XXX
XXX
1
4.8
XXX
XXX
...
?
?
?
1��2.4��XXX��XXX
2��3.6��XXX��XXX
1��4.8��XXX��XXX
...
����B�ĸ�ʽ
id
count
�����ֶ�1
�����ֶ�2
2
8
XXX
XXX
2
4
XXX
XXX
1
3
XXX
XXX
...
?
?
?
?
2��8��XXX��XXX
2��4��XXX��XXX
1��3��XXX��XXX
?
��������case�Ľ�����Ӧ�ñȽ�����������,�������ҾͲ������ˣ�ֱ���ϴ��룺
map(K1?key,?Text?value,?OutputCollector<K2,?V2>?output,?Reporter?reporter)
{
���ȴ����õ����������ж�Ŀǰ���ڶ���һ���ļ������ݼ����д���
If(?��A�ļ�������?)
��
Split(",")�õ�?�Լ����ĵ�id��price�����ֶΡ�
//������ЩС���ɣ�����ͨ��id����ֶ���key���ǽ��������ļ���ͬһ��key�����ݾͻ���ƽ̨����鲢��һ�𣬼��ϡ�PRICE����ǰ��Ϊ�˸����㣬ȷ���������ݡ�
Output.emit(id,"PRICE:"+price);
��
If(?��B�ļ�������?)
��
Split(",")�õ�?�Լ����ĵ�id��count�����ֶΡ�
Output.emit(id,"COUNT:"+count);
��
}
?
//ƽ̨��ÿ��key�����ݹ鲢��һ��ʱ���ͻ��кܶ��������¸�ʽ����Ϣ��
?
����?id=1��KEY��Ӧ����������Ϊ��?
PRICE:2.4
PRICE:4.8
COUNT:3
...
?
void?reduce(Text?key,?Iterator<Text>?values,
??????????????OutputCollector<Text,?Text>?output,?Reporter?reporter)
{
float?priceSum?=?0.0;
long?countSum?=?0;
for(?Text?value?:values)
{
���ݡ�PRICE�����͡�COUNT����ǰ�������ݴ���ʲôֵ
if(?��price)
priceSum?+?=?price��
else?if(?��count)
countSum?+=?count;
}
output.collect(key,"PRICESUM:"+priceSum?+"/t"+"COUNTSUM:"+countSum?);
}
�Dz��Ǻܼ�SO?EASY��
?
�����棬�ֲ�ʽ����ƽ̨���������Ѿ��н��˹�˾WSD��ISD��SOSO���������BU�Լ�ϵͳ�����ݷ�������������ϵͳ�����ȶ�����ͨ������ƽ����չ�ķ�ʽά����һ�������ݷ������ܣ������λͬ���к������ݵķ�����������ϵ����ƽ̨��-�ֲ�ʽ����ƽ̨��Ŀ�飺tedxu,jakegong,joeyli,stevenshi...
mapreudce���뷽ʽĿǰֻ�����ǵ�һ�����ݷ���������뷽ʽ��java,C++,SQL�ű���shell,python..�Ƚű�������ʵ�ַ�������ı�д
ϣ���ֲ�ʽ����ƽ̨��������ҽ���������ݴ������⣬лл����
?
�κ�һ��������������������������죬�ڲ��ϳ��ֵ�Ӧ����ǰ��һ����ϱ�¶�����⣬��¶�������Ҫ�����
����1.��ͬһ��KEY����������ݲ���̫�ࡣ
�������£�
?
?���������µ�����(�Ҿ������ֶ�)��
?����????????????? QQ����???????? �Ա�
?www.qq.com?? 21201421????? ��
?....
?����Ҫ���������¹��ܵ�ͳ�� select count(distinct QQ����) from ����Դ group by �Ա�
?
?�����ϴε����£����ǿ��ܵ��������£�
?map(K1 key, Text value, OutputCollector<K2, V2> output, Reporter reporter)
?{
??? //��γ�ȡ�ֶ��ҾͲ���˵�ˣ����Ӧ�ö�����ˡ�
??? //�ؼ��������KEY��ȡֵ��
??
?? ?key = �Ա�+"_UV";
??? value = QQ����
??? //���ҵ���key->value�Է��������??
??? Output.emit(Key ,value);?
?}
?
?2.Reduce������Ҫ��ʲô
?
?void reduce(Text key, Iterator<Text> values,
?
?????????????? OutputCollector<Text, Text> output, Reporter reporter)
?
?{
?
??if( postFix( key ) == "_UV" ) //�ж��Ƿ����û������ָ����ص�����
??
??��
??
????//values�е����ݾ��ǴӸ�̨�����Ϲ��ܹ�����QQ����
??
????String uv = distinctCount( values );
??
????//push�����ս��
??
????Output.emit(key,uv );
??
??��
?
?}
?
??????�����ķ�ʽէ����ȥûʲô���⣬������������ύ�����п��ܽ�����������̳ű�������������ִ�У������������أ�
???? �ؼ�����KEYֵ�����ɣ���Ϊ��������ǰ����Ա����ͳ�Ʒ���������Ȼ���ջ�������KEY��"����_UV","Ů��_UV",Ҳ����˵���jobֻ������reduce�����������Ե�QQ����Ἧ�е�һ̨����������Ů�Ե�QQ����Ҳ�Ἧ�е�һ̨��������͵��³е�reduce����Ļ������ع�������漰�����������ܿ�������ͻ�ִ��ʧ�ܡ�
??
? ������������ش�Ҷ��Ѿ�����ˣ���ô��ν����������أ�
? ����취����KEY��ɢ��
??
? �����������
? map(K1 key, Text value, OutputCollector<K2, V2> output, Reporter reporter)
?{
??//�ؼ��������KEY��ȡֵ,���ǰ���QQ�����5��λ�������ݴ�ɢ��
??key = �Ա�+"_UV_"+$func_ȡQQ�������λ(QQ����);
??value = QQ����
??//���ҵ���key->value�Է��������??
??Output.emit(Key ,value);?
?}
?
?2.Reduce������Ҫ��ʲô��reduce���벻���κα仯��
?
?void reduce(Text key, Iterator<Text> values,
?
?????????????? OutputCollector<Text, Text> output, Reporter reporter)
?
?{
?
??if( postFix( key ) == "_UV" ) //�ж��Ƿ����û������ָ����ص�����
??
??��
??
????//values�е����ݾ��ǴӸ�̨�����Ϲ��ܹ�����QQ����
??
????String uv = distinctCount( values );
??
????//push�����ս��
??
????Output.emit(key,uv );
??
??��?
?}
?
?�����ͻ��кܶ�����������¸�ʽ��KEY "����_UV_00000" "����_UV_00001" "����_UV_00002" ..... "����_UV_99999" (Ů��ʱһ��)
?Ҳ����˵
?ԭ����ͳ�ƽ��Ϊ��
?����_UV: XXXXXX
?��_UV��XXXXXX
?
?�����ڵ�ͳ�ƽ��Ϊ��
?��00000��β�����Ե�QQ����_UV: XXXXX
?��00001��β�����Ե�QQ����_UV: XXXXX
?��00002��β�����Ե�QQ����_UV: XXXXX
?.....
?��99999��β�����Ե�QQ����_UV: XXXXX
?
?��00000��β��Ů�Ե�QQ����_UV: XXXXX
?��00001��β��Ů�Ե�QQ����_UV: XXXXX
?��00002��β��Ů�Ե�QQ����_UV: XXXXX
?.....
?��99999��β��Ů�Ե�QQ����_UV: XXXXX
?
?�õ��������һ��ͳ�Ʋ����Ϳ��Եõ�����ָ�������ˡ�
?
��ģ���������hadoopƽ̨������Э��ͨѶ�Ļ�����Hadoopƽ̨�����е�Э����ö���ͨ�������ƽ���ʵ�֡�
?
������ͣ�
Զ�̽��̵���
client����Զ��Server��ijʵ���ķ�����
��
����ʵ�֣�
Զ�̹��̵��ã�һ��ͨ��������з��������Լ�����ֵ��Ϣ���䣬��ģ�����Ҫ����ͨ�õ�����Server���ʵ�ַ�ʽ������Socket����Server������,�������Ϲ���һ������ҵ��ʵ����client���������ò�������һ����ʽ�������л���ͨ�����紫�䵽Server�ˣ�Server�����û����������Ӧ��ʵ��������������ֵ���߲�����쳣ͨ�����練����client��
�����漰������Ҫ��Ϊ��
Org.apache.hadoop.ipc.Server�Լ����ڲ�ʵ����
org.apache.hadoop.ipc.Client�Լ����ڲ�ʵ����
org.apache.hadoop.ipc.Rpc$Server
?
�ͻ��ˣ�client������ʵ�֣�
?
�ͻ�����Ҫͨ��proxyģʽ,����java������̬��������,Proxy.newProxyInstance
public?static?Object?newProxyInstance(ClassLoader?loader,
??Class<?>[]?interfaces,
??InvocationHandler?h)
�ú�����Ҫ����������Class<?>[]?interfaces,?InvocationHandler?h
�û����øú�������һ��Objectʵ������ʵ����һ��ʵ����interfaces�ӿڵľ���ʵ�����û�ͨ�������ص�Objectת��Ϊ�����interfaces����ʹ��,���û����ø�ʵ����ʵ����interfaces�ӿڣ�ij�����巽��ʱ,ϵͳ�ͽ�����ת����InvocationHandler?h���������Ӧ��ʵ����
public?interface?InvocationHandler?
{
????public?Object?invoke(Object?proxy,?Method?method,?Object[]?args)
throws?Throwable;
}
�����û�������push��InvocationHandler?h���������invoke������ϵͳ��method�Լ�args�����������������л���ͨ�����紫�䵽server�ˡ�
?
��Ҫ�������£�����Invoker��һ��ʵ����InvocationHandler?�ӿڵ���
1.���ɴ���
?
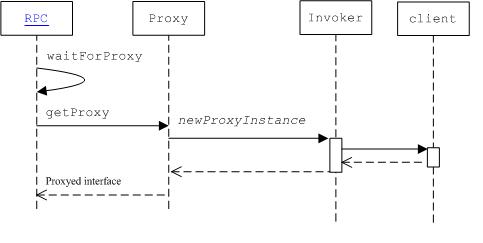
����Զ�̴�������Ҫ�ؼ��������java�Ķ�̬��������?Proxy.newProxyInstance.
?
2.Զ��ʵ���������ã�
?
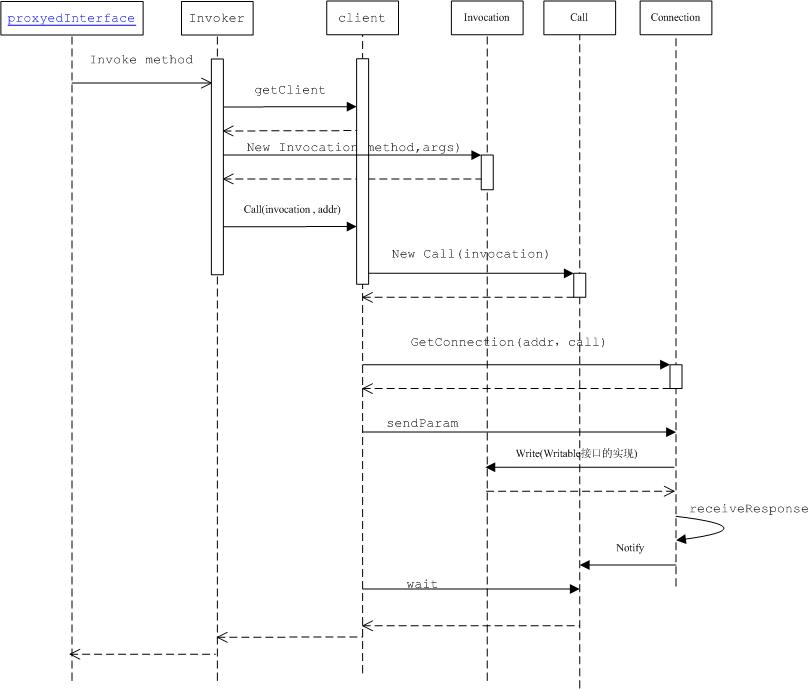
�����û�������push��InvocationHandler?h���������invoke������ϵͳ��method�Լ�args�����������������л���ͨ�����紫�䵽server�ˣ�ʵ����Invoker��ͬʱ��ʵ����һ��Client��ʵ�������client��Ҫ�����÷����Լ��������л��Ժ�ͨ�����紫�䵽Server�ˣ���
Զ�̵��õ���Ҫ�ؼ�����Invocationʵ����Writable�ӿ�,Invocation��write(DataOutput?out)�����н����õ�methodNameд�뵽out�������÷����IJ�������д��out?��ͬʱ�����������classNameд��out,������в������д��out,��Ҳ�;�����ͨ��RPCʵ�ֵ��õķ����еIJ���Ҫô�Ǽ����ͣ�Ҫô��String,Ҫô��ʵ����Writable�ӿڵ��ࣨ�����Լ�֪��������л���stream����Ҫô�����飨�����Ԫ��Ҳ����Ϊ������,String,ʵ����Writable�ӿڵ��ࣩ��
Invocation���л�������ʵ����ͨ�����º���ʵ�ֵ�:
Org.apache.hadoop.io.ObjectWritable.writeObject
(DataOutput?out,?Object?instance,
Class?declaredClass,?Configuration?conf);
{
if?(instance?==?null)
{?//?null
instance?=?new?NullInstance(declaredClass,?conf);
declaredClass?=?Writable.class;
}
//�������������out
UTF8.writeString(out,?declaredClass.getName());?//?always?write?declared
//���������
if?(declaredClass.isArray())
{?//?array
int?length?=?Array.getLength(instance);
//����д������Ԫ�ظ���
out.writeInt(length);
//�����л������е�Ԫ��
for?(int?i?=?0;?i?<?length;?i++)
{
writeObject(out,?Array.get(instance,?i),?declaredClass
.getComponentType(),?conf);
}
?
}
//
else?if?(declaredClass?==?String.class)
{?//?String
UTF8.writeString(out,?(String)?instance);
?
}
else?if?(declaredClass.isPrimitive())
{?//?primitive?type
?
if?(declaredClass?==?Boolean.TYPE)
{?//?boolean
out.writeBoolean(((Boolean)?instance).booleanValue());
}
else?if?(declaredClass?==?Character.TYPE)
{?//?char
out.writeChar(((Character)?instance).charValue());
}
else?if?(declaredClass?==?Byte.TYPE)
{?//?byte
out.writeByte(((Byte)?instance).byteValue());
}
else?if?(declaredClass?==?Short.TYPE)
{?//?short
out.writeShort(((Short)?instance).shortValue());
}
else?if?(declaredClass?==?Integer.TYPE)
{?//?int
out.writeInt(((Integer)?instance).intValue());
}
else?if?(declaredClass?==?Long.TYPE)
{?//?long
out.writeLong(((Long)?instance).longValue());
}
else?if?(declaredClass?==?Float.TYPE)
{?//?float
out.writeFloat(((Float)?instance).floatValue());
}
else?if?(declaredClass?==?Double.TYPE)
{?//?double
out.writeDouble(((Double)?instance).doubleValue());
}
else?if?(declaredClass?==?Void.TYPE)
{?//?void
}
else
{
throw?new?IllegalArgumentException("Not?a?primitive:?"
+?declaredClass);
}
}
else?if?(declaredClass.isEnum())
{?//?enum
UTF8.writeString(out,?((Enum)?instance).name());
}
//����Ԫ��ͨ������ʵ�ֵ�writable�ӿڹ���ʵ�����л�
else?if?(Writable.class.isAssignableFrom(declaredClass))
{?//?Writable
UTF8.writeString(out,?instance.getClass().getName());
((Writable)?instance).write(out);
?
}
else
{
throw?new?IOException("Can't?write:?"?+?instance?+?"?as?"
+?declaredClass);
}
}
?
?
����ˣ�Server,�������ʵ�����ڣ�����ʵ�֣�
1.���������
?
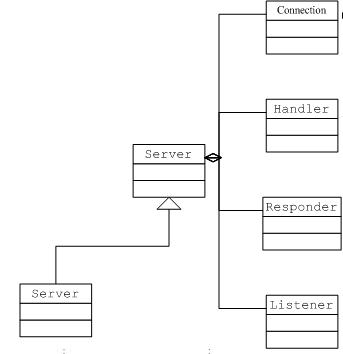
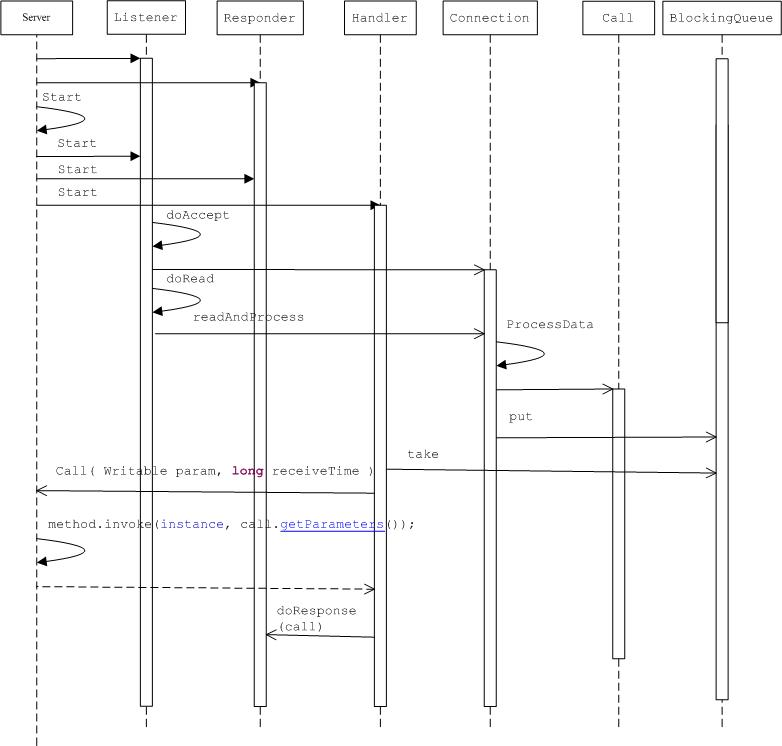
��ײ�ij�����Server����������ͨѶ�ĺ��ģ����Listener��Responser�Լ�Handlerʵ���ij�ʼ�������������й���ģ��������������
Listener��Ҫ����Socket�ļ����Լ�Connection�Ľ�����ͬʱ���ClientSocket�����ݿɶ��¼���֪ͨConnection����processData���յ����������Ժ�װΪһ��Call������Connection�����������ж�ȡ�IJ�����Ϣ,���÷�����Ϣ�������������С�
Handler��Ҫ��������������ȡ������������д��������յ���Server�齱���call������Ŀǰ������Serverʵ����һ�������ʵ���࣬����Ҳ��Server��Server��call�����и��ݷ������Լ���������method������ʵ�ʷ����ʵ�������Ͻ��з������á��������÷���ֵ���쳣�������л���һ��ByteBuffer,��Responser.doRespond�������з������ݡ�
Responser����Ҫ�����Ƿ�������,����������Ƚϴ�һ�η��Ͳ���ȥ���ͼ���Write�¼���һֱSelect�Ƿ��д����֤���ݷ�������.
2.Server����ص�������ͼ���£�
?
���˼��
?
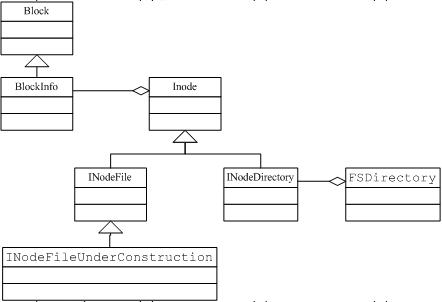
HDFS�ж����ݴ洢����С��λΪblock,HDFS�Ὣ��洢�Ĵ��ļ���ɢ�ɺܶ�64M��С��block��������Щblock�ֱ�洢�ڼ�Ⱥ��datanode�����ϡ�������namenode��Ҫ�洢�ļ�Ԫ������Ϣ���ļ�Ŀ¼�ṹ�������ļ�����Щblock��ɣ����ò�����Ҫ�漰�Ĺؼ�����Ϊ��INode,INodeFile,INodeDirectory,Block,BlockInfo,FSDirectory?
NameNode��Ҫ����洢�ļ�Ŀ¼�ṹ�Լ������ļ�����Щblock�����ЩԪ���ݻ�����Ϣ,���϶��������namenode�ϡ������������Ҫ��ϵ���¡�
?
?
INode
?
INode�dz�����࣬���������ܹ��˽����ʾһ���ļ�����Ŀ¼�ṹ�е�һ���ڵ㣬����������Ҫ����Ϊ��?
??//�ڵ�����
??protected?byte[]?name;?
??//���ڵ�
??protected?INodeDirectory?parent;
??//�����ʱ��
??protected?long?modificationTime;
??//����ʱ��
??protected?long?accessTime;
??//����Ȩ�ޣ�ͬlinux?0777,0666?֮�ࣩ
??private?long?permission;
?
INodeFile
?
INodeFile�̳���INode����ʾ�ļ��ڵ㡣?��������Ҫ�������£�
?//���ļ��а���������Block����Щ��������ʵ�ʵ��ļ�block���ݣ���Ҫ������Ϊblocks������ͨ��blockID��ʱ�����Ϣ�����ҵ���ЩBlock������̨datanode�����ϣ��ͻ���ֱ�����datanode�������ӣ��������BockID��Ӧ��Block�о����ļ��������ݣ������ٽ�,���ֶ�Ϊ�ؼ��ֶΣ�
?protected?BlockInfo?blocks[]?=?null;
?//block�ĸ��Ƹ���
?protected?short?blockReplication;
?//ȱʡblock��С
?protected?long?preferredBlockSize;
?
?INodeDirectory
?
INodeDirectoryͬ���̳���INode����ʾ�ļ�Ŀ¼�ڵ㣬��Ҫ�������������£�
?//���ļ�Ŀ¼�����е��ӽڵ���Ϣ
?private?List<INode>?children;
?
?Block
?public?class?Block?implements?Writable,?Comparable<Block>
?
?Block������һ���������ͱ�ʾHDFS��һ����С�洢��Ԫ������Ҫ�������������£�
?//BlockID��ʶ
?private?long?blockId;
?//���Block���������ֽ�����
?private?long?numBytes;
?//һ��ʱ���,��ʾBlock�İ汾
?private?long?generationStamp;
?
?ע�����Block����ֻ��һ������ĸ�����������Ϊһ�����ݿ�ı�ʶ,һ���洢��Ԫ�ı�ʶ���������������ʵ��Block���ݡ�
?
Block��Ϣ�Ķ�ȡ����clientͨ�����紫��һ�����л���block����DataNode,DataNode�ڱ����еĶ�ȡ���Block��Ӧ�Ĵ洢�ļ������ظ��ͻ��ˡ�
Block��һ��ʵ����Writable,?Comparable<Block>�Ķ���˵��Block������Խ������л���ͨ��������д��䣬DataNodeҲ����ͨ��HashMap�ķ�ʽ��Block��ʵ�ʵĴ洢�ļ����ж�Ӧ������
?
?BlockInfo
?
?BlockInfo�̳���Block,���������Ҫ�������£�
?//��Block�������ļ�
?private?INodeFile??????????inode;
?/**
?????*?This?array?contains?triplets?of?references.
?????*?For?each?i-th?data-node?the?block?belongs?to
?????*?triplets[3*i]?is?the?reference?to?the?DatanodeDescriptor
?????*?and?triplets[3*i+1]?and?triplets[3*i+2]?are?references?
?????*?to?the?previous?and?the?next?blocks,?respectively,?in?the?
?????*?list?of?blocks?belonging?to?this?data-node.
?????*/
?private?Object[]?triplets
?
?
triplets��һ���ؼ��ֶΡ�
ͨ��triplets[3*i+1]?��?triplets[3*i+2]���Եõ�ij̨datanode���������е�block�б���triplets[3*i+1]?��triplets[3*i+2]ΪBlockInfo���Ͷ���
�������ҪӦ����DatanodeDescriptorʵ����
private?volatile?BlockInfo?blockList?=?null?����ֶ��С�
?
ͨ��triplets[3*i]���Եõ����Block��������������datanode��λ��,triplets[3*i]ΪDatanodeDescriptor���Ͷ���
?
ץסBlockInfo��ץס������HDFS��Block�����ļ��ֲ�ʽ�洢�Ĺؼ���
BlockInfo��Ϣ�в���������һ��Block���洢����ЩDataNode��,��������ij������datanode�ϴ洢������Block��Ϣ���Լ���block������һ��INodeFile���û���Ҫ��ȡ�ļ�ʱ����ͨ��INodeFile�õ�����ļ����е�Block---INodeFile�е�?BlockInfo[]?getBlocks()?������ͨ��BlockInfo�ֿ��Եõ�Block�洢��DataNodeInfo�б���?�û��Ϳ�����õ���DataNode�б��Ļ������Ͷ�ȡBlock�������ݵ������ⲿ�־���ʵ�ֺ����ٽ�����
?
?
��ϵͳ���й����У������ؼ�������Ҫ�洢���ڴ��У�Ҳ����˵HDFS��Namenode��һ���ڴ澵�����е����ݾ������϶�����ɵ����νṹ,Ҳ�����˻��ʣ����Namenode���������ʲô�����أ���������ʵúã���������Ľ���취��������ϸ���⣬Ŀǰ����һ�£�
HDFSΪ���ܹ���֤���ݰ�ȫ�ԣ������ԣ����ú����ݿ�һ�������ֻ��ƣ���¼���ݲ�����Ϊ��־����Ӧ�Ĺ��ܶ���ΪFSEditLog?��?
ϵͳ��ʱ���ڴ��е��ļ�ϵͳ�ṹ�������л������̣�FsImage��,��ɾ����ǰ��EditLog?��?���ϵͳ����������Namenode��Ӿ����ļ��ж�ȡĿ¼�ṹ��Ϣ��ͬʱִ��EditLog�м�¼�IJ��������Իָ����µ��ڴ澵��?
?
FSDirectory?
FSdirectory��һ����Ҫ�����Ǿ���������˵�ĴӾ����ļ��ж�ȡĿ¼�ṹ��Ϣ��ͬʱִ��EditLog�м�¼�IJ��������Իָ����µ��ڴ澵��
FSdirectory��һ����Ҫ���þ��Dz���INodeDirectory��INodeFile�����ļ�ϵͳ��Ŀ¼���ļ��Լ��ļ�������Block���в�����FSdirectory��һ���ؼ����ԣ�rootDir����������������ļ�ϵͳ�ĸ�Ŀ¼��
�ö����漰����Ҫ�������£�
?
void?loadFSImage(Collection<File>?dataDirs,?Collection<File>?editsDirs,StartupOption?startOpt)?throws?IOException
?
boolean?mkdirs(String?src,?PermissionStatus?permissions,
boolean?inheritPermission,?long?now)
?
Block?addBlock(String?path,?INode[]?inodes,?Block?block)?throws?IOException
?
private?<T?extends?INode>?T?addChild(INode[]?pathComponents,?int?pos,T?child,?long?childDiskspace,?boolean?inheritPermission)
throws?QuotaExceededException
?
?
INodeFileUnderConstruction
?
�����̳���INodeFile,����ʵ������һ�����ڴ���д��״̬���ļ������ļ��Ĵ������ļ����ӣ��ļ���ĿǰHDFS֧�ֲ��Ǻܺã�ʱ����ʹ�õ��������,INode��һ������??boolean?isUnderConstruction(),��������������true,��ʾ�������Ŀǰ����д��״̬�����Խ������������ת��ΪINodeFileUnderConstruction��
���ļ�����isUnderConstruction״̬ʱ�������ͺ��ļ���Լ������������Ϊ�ļ���д�������������ʵ������һ����Լ����Լ��ר��һ�½��н��⣩,��FSNameSystem��startFileInternal���������еIJ�����������Կ������ߡ�
//�����ж��ļ��Ƿ���ڣ����Ҵ����ļ�д��״̬
if?(myFile?!=?null?&&?myFile.isUnderConstruction())
{
//ת���ļ�ΪINodeFileUnderConstruction����
INodeFileUnderConstruction?pendingFile?=?
(INodeFileUnderConstruction)?myFile;
//?If?the?file?is?under?construction?,?then?it?must?be?in?our
//?leases.?Find?the?appropriate?lease?record.
?
//����ļ�����д��״̬һ������Լ��֮��Ӧ
Lease?lease?=?
leaseManager.getLease(new?StringBytesWritable(?holder));
?
�������Ƿ���һ��INodeFileUnderConstruction�Ĺؼ������Լ�����
INodeFile������������ʾһ���ļ��ڵ㣬���Ĵ����Զ�����BlockInfo��صġ�
��INodeFileUnderConstruction�ͻ���һЩ�ļ������Լ���ʱ��Ҫ����Ϣ,,��ϸ���£�
//������Ա�ʾ��ǰ�ļ�����Լ�������Ĵ�Ӧ��
StringBytesWritable?clientName?=?null;?//?lease?holder
StringBytesWritable?clientMachine?=?null;
//client�ܿ���Ҳ��datanode����֮һ
DatanodeDescriptor?clientNode?=?null;?//?if?client?is?a?cluster?node?too.
?
//���������ҪӦ����block��recover�������ò�����������ϸ������
private?int?primaryNodeIndex?=?-1;?//?the?node?working?on?lease?recovery
//�ļ����һ��block��Ҫд��Ļ��������Ǻ���Ҫ�����ԣ�Ҳ���Զ����ģ��ļ�����д��һ���Ƕ����һ��Block���в���
private?DatanodeDescriptor[]?targets?=?null;?//?locations?for?last?block
private?long?lastRecoveryTime?=?0;
?
���濴һ������Ҫ�ķ���,���������������ϸ������
void?assignPrimaryDatanode()
���ļ�д������У��ܿ�����ijЩdatanode��д��ʧ�ܣ������Ҫ��block����recover���������ָ������е����ڵ������Щд��������datanode��
?
�����Ѿ��ᵽ��HDFS�д洢���ݵ���С��λ��BLOCK,һ���ļ���Ӧ������BLOCKȫ������һ���IJ�����Դ�����DataNode��;����Ҳ�ᵽnamenode����洢�ļ�ϵͳ��Ԫ������Ϣ���ļ�Ŀ¼�ṹ���Լ��ļ�����������block��.?��client�û������ȡij���ļ�ʱ��client����ͨ��RPC�ķ�ʽ����NameNode�ϵķ���ģ�飬�õ�һ���ļ�����������BLOCK�б����Լ���ЩBlock���ڵ�Datanode��Ϣ��?���client����Ӧ��Datanode�������ӣ����Ͷ�ȡBLOCK������
��ôNamenode���֪���ļ���block��������̨datanode�ϣ��Լ�������ι�����Щ��Ϣ�ģ�
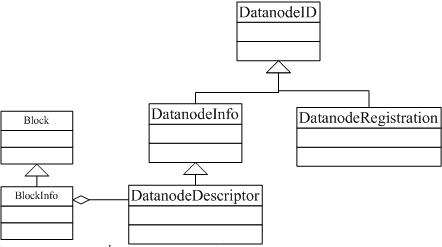
�����Ѿ��ᵽ�������ؼ��ࣺ
1.Block,BlockInfo,DataNodeID,DataNodeInfo,DataNodeDescriptor,BlockMap���ص㣩
Block��BlockInfo������ǰ���Ѿ�����ϸ��˵�������ﲻ�����������ٴ�����һ�㣬BlockInfo���и��dz��ؼ������Ծ��ǣ�triplets��
����Ҫ�����������ܡ�
1.˫������
triplets[3*i+1]?��?triplets[3*i+2]?�洢BlockInfo���Ͷ���
�������ֶ���Ҫ�洢ijһ̨DataNode���������е�Block�б���
?
2.����
triplets[3*i]?�洢DataNodeDescriptor���͵Ķ���
����ֶ���Ҫ�洢���Block���洢����ЩDataNode�ϡ�
?
ע������������û��̫���ֱ����ϵ����Ҫ������
?
�����˽�һ�¼����ص��ࣺ
?
?
 ?
?
DatanodeID
public?class?DatanodeID?
implements?WritableComparable<DatanodeID>
?
����������ȫ��ʶһ��DataNode,�ȿ�һ�������Ĺؼ��ֶ�
??public?String?name;??????///?hostname:portNumber
??public?String?storageID;?//unique?per?cluster?storageID
??protected?int?infoPort;//the?port?where?the?infoserver?is?running
public?int?ipcPort;//?the?port?where?the?ipc?server?is?running
?
nameֱ���������ؼ����:hostname:portNumber
StorageID:��ʾdatanode�Ĵ洢ID���ⲿ�ֵ���ع������Ǻ������н��ܣ�
infoPort:InfoServer�������Ķ˿�
ipcPort:IPC�����������Ķ˿�
?
����������һ��Server������������������Ϣ��
?
DatanodeInfo
/**?
??*?DatanodeInfo?represents?the?status?of?a?DataNode.
??*?This?object?is?used?for?communication?in?the
*?Datanode?Protocol?and?the?Client?Protocol.
*?ͬʱ�����Ҳ�洢DataNode���������绷���Ľڵ���Ϣ��
?*/
public?class?DatanodeInfo?extends?DatanodeID?implements?Node?
?
����Ĺؼ��ֶΣ�
protected?long?capacity;
??protected?long?dfsUsed;
protected?long?remaining;
protected?long?lastUpdate;
protected?int?xceiverCount;
protected?String?location?=?NetworkTopology.DEFAULT_RACK;
?
����ö����������ؼ��ֶ�
private?int?level;?//which?level?of?the?tree?the?node?resides
private?Node?parent;?//its?parent
�������ֶα�ʾ��datanode�ڵ����������˼ܹ��е����λ����Ϣ��
?
��Щ�ֶζ�����ֱ�Ӵ��������˽���ʵ�ֵ����á�
?
?
?
DatanodeDescriptor
public?class?DatanodeDescriptor?extends?DatanodeInfo
?
����������˵�ͱȽϸ���һЩ��������ʵ��������Namenode?Server��,����ܶ�ʵʱ��Ϣ���ö����������Ҫ�ļ�����
?
��������������Ҫ���ڲ��ࡣ
BlockIterator
BlockTargetPair
BlockQueue
?
BlockIterator�������������оͿ����˽������Ҫ�������Ƕ����DataNode�����е�Block��Ϣ���б����������֪�����������̽����ľ���DatanodeDescriptor��private?volatile?BlockInfo?blockList?=?null?����ֶ�,?BlockInfo�е�triplets[3*i+1]?��?triplets[3*i+2]��
�������������£�
�������õ�������current����ΪDatanodeDescriptor?�е�?blockList������current.findDatanode(this)�����õ�DatanodeDescriptor��blockInfo��?triplets���������λ��index���������triplets[index*3+2]�õ����datanode����һ��BlockInfo,�������BlockInfo����Ϊcurrent��
?
BlockTargetPair���������Ҫ����һ��Block��һ��DatanodeDescriptor��Ϣ����ҪΪ�˷�������ģ���������datanode�Ͻ��жԸ�Block�IJ�����
?
BlockQueue�������ʵ�ʾ���һ��BlockTargetPair����Ķ��С�
?
������������ϸӦ�����Ǻ����������ۣ�������ҪĿ�ľ����˽�block�����datanode�ڵ㽨����Ӧ��ϵ��
?
?
BlockMap
public?class?BlocksMap
?
����������DZ��ڵ���ͷϷ:BlockMap,�������Ȼ���Ƿdz���Ҫ,�������ᴩ������HDFS�ܹ�,�������Ҫ�Ƕ�BlockInfo�����ķ�װ��
���ǿ���BlockMap�������ڲ���,һ������������ǰ���ܹ���BlockInfo,��һ������NodeIterator��
?
BlockInfo���ﲻ������
public?static?class?BlockInfo?extends?Block
?
NodeIterator?
private?static?class?NodeIterator?implements?Iterator<DatanodeDescriptor>
?
�������Ҫ�����Ƕ�ij������block���ڵ�����DataNode�ڵ���Ϣ���б���,����Ҫʵ�־���ͨ��BlockInfo�е�triplets[3*i]?���ⲿ�ִ���Ƚϼ�����Ͳ���ϸ���з����ˡ�
?
���濴һЩ��Ҫ�ķ�����
?
1.
BlockInfo?addINode(Block?b,?INodeFile?iNode)
{
BlockInfo?info?=?checkBlockInfo(b,?iNode.getReplication());
info.inode?=?iNode;
return?info;
}
?
���������ҪӦ�����û����½����ļ�����д����ʱ,Namenode��Ҫ�´���һ��block����ʶ�û�д�������(��Ӧ��Datanode��һ�������block�ļ�)��һ��blockд��ʱ��һ��Ϊ64M��,�ֻ��½�һ��block��ʶ�����û�д������ݡ���Щ�½���block��Ҫ���ӵ�INodeFile�е�BlockInfo���顣
loadFSImage(),�������ͬ����Ҫ������������ĵ��ã����ļ�ϵͳ��Ԫ������Ϣ���ļ�����ָ����ڴ澵��
?
?
2.
/**
?*?Add?BlockInfo?if?mapping?does?not?exist.
?*/
private?BlockInfo?checkBlockInfo(Block?b,?int?replication)
{
BlockInfo?info?=?map.get(b);
if?(info?==?null)
{
info?=?new?BlockInfo(b,?replication);
map.put(info,?info);
}
return?info;
}
���������ֻҪĿ�ľ��ǽ���block��blockinfo��ӳ���ϵ,����ͨ���������RPC����ʱһЩ������Block���͵ġ�����datanode����ʱ�ϱ����е�block��namenode����Ϊblockinfo�������ֻ�Ǵ�����Namenode?Server�ϵġ�
?
3.
/**?Returns?the?block?object?it?it?exists?in?the?map.?*/
BlockInfo?getStoredBlock(Block?b)
{
return?map.get(b);
}
ͨ��һ��block������Namenode����֮��Ӧ��blockinfo����
?
4.
Iterator<DatanodeDescriptor>?nodeIterator(Block?b)
{
return?new?NodeIterator(map.get(b));
}
���������ᵽ��һ��DatanodeDescriptor������,�����洢ͬһ��block������datanode��Ϣ��
���������Ҫ��Ӧ�����û�ͨ��client��HDFS�е��ļ����ж�ȡ�Ĺ���,Namenode�᷵��һϵ�а���block�Լ�datanodeinfo[]?�Ķ���?���е�datanodeinfo�������ͨ�������������ȡ������datanode�б���
?
5.
/**
?*?Remove?the?block?from?the?block?map;?remove?it?from?all?data-node?lists
?*?it?belongs?to;?and?remove?all?data-node?locations?associated?with?the
?*?block.
?*/
void?removeBlock(BlockInfo?blockInfo)
{
if?(blockInfo?==?null)
return;
blockInfo.inode?=?null;
for?(int?idx?=?blockInfo.numNodes()?-?1;?idx?>=?0;?idx--)
{
DatanodeDescriptor?dn?=?blockInfo.getDatanode(idx);
dn.removeBlock(blockInfo);?//?remove?from?the?list?and?wipe?the
//?location
}
map.remove(blockInfo);?//?remove?block?from?the?map
}
Ӧ����namesystem.commitBlockSynchronization������,���������������Ҫԭ����ϵͳ��������recoverBlock������
6.
void?removeINode(Block?b)
{
BlockInfo?info?=?map.get(b);
if?(info?!=?null)
{
info.inode?=?null;
if?(info.getDatanode(0)?==?null)
{?//?no?datanodes?left
map.remove(b);?//?remove?block?from?the?map
}
}
}
�÷�����ҪӦ���ڣ��û������ļ��������ļ�����д������������Ҫ��namenode����ע���µ�block,�����ӵ�INodeFile�����block�����У�Ȼ������datanode���Դ���дblock�Ĺܵ�,�������ʧ��,�͵��ø÷�������һ����Ŀ�ľ���ɾ����һ����ע���block��
ͬʱ���÷�����Ӧ�����û�ɾ���ļ�������
?
7.
boolean?removeNode(Block?b,?DatanodeDescriptor?node)
{
BlockInfo?info?=?map.get(b);
if?(info?==?null)
return?false;
?
//?remove?block?from?the?data-node?list?and?the?node?from?the?block?info
boolean?removed?=?node.removeBlock(info);
?
if?(info.getDatanode(0)?==?null?//?no?datanodes?left
&&?info.inode?==?null)
{?//?does?not?belong?to?a?file
map.remove(b);?//?remove?block?from?the?map
}
return?removed;
}
�÷����Ӳ����Ϳ��Կ����������õ���Ҫԭ�����ijһ��DataNode�ڵ�ʧЧ������ij��DataNode�ڵ��ij������blockʧЧ��
?
?��leaseһ�������Ѿ����ļ�������������һ�������˽⣬
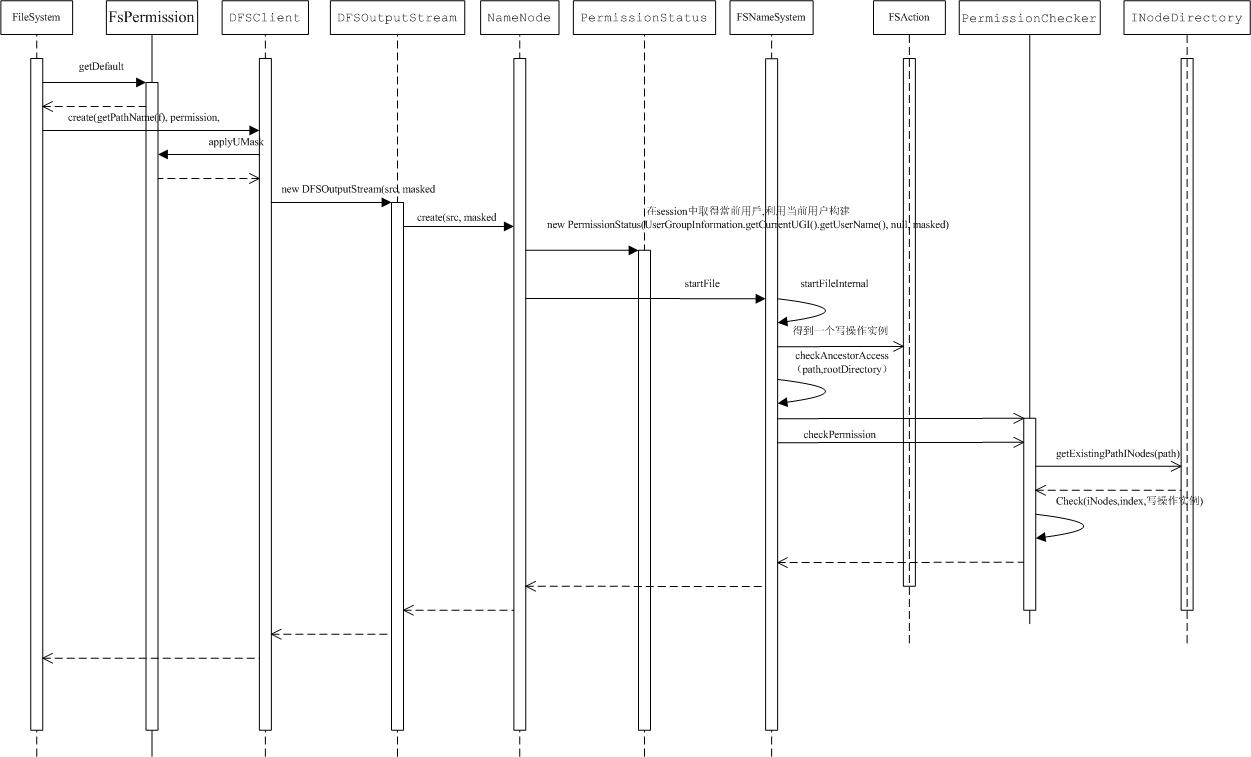
�ļ��Ĵ�����Ҫ��ͨ���ṩ���û�ǰ��㹤�߳�����FileSystem,�����HDFS�����ľ���ʵ��ΪDistributedFileSystem��
�ļ��еĴ�����һ����ԼĹ��̣���Ҫ��ͨ��FileSystem�е�mkdirs�������������������DFSClientʵ���е���ͬ������mkdirs������ͨ��Hadoop������RPC���Ƶ���Namenode��mkdirs���������������������PUSH��FSNameSystem��mkdirsInternal���������������Ҫ���Ǽ������Ȩ�ޣ����ͨ��FSDirectory��unprotectedMkdir��������������һ��INodeDirectoryʵ�����ӵ��ļ�ϵͳ��Ŀ¼���С�
�ļ��ڵ�Ĵ�����������ԱȽ��鷳����Ҫ�������£�
FileSystem��create��������һ������Ҫ����FSDataOutputStream����һ��Ҳ�ȽϺ����⣬����java�е��ļ���һ��������һ���ļ�д�������ļ����ݽ����ӣ��������ǿ��ļ�������namenode��Ҫ����ʲô���飨Ȩ����֤�Լ���Լ��֤��Щǰ�涼�Ѿ����ᵽ����������ݾͻ��ӹ���һ���֣�
DfSOutputStream��ʵ������ʱ��ͨ��Hadoop������RPC���Ƶ���Namenode��create�����������������PUSH��FSNameSystem��StartFileInternal��������Ҫ��Ȩ����֤����Լ����ȹ��������������Ҫ���þ��Ǵ���һ��INodeFileUnderConstructionʵ���������Ѿ�������ļ�д������ж�����һ��INodeFileUnderConstruction������ļ���Ӧ�������ʵ�����ͨ��FSDirectoty��addNode()�������ӵ��ļ�ϵͳĿ¼���У����ʱ���ļ��������������������Ҫ�ĵ�һ�����ļ�ϵͳ���Ѿ���������ļ��ļ�¼��
������漰���ļ���д��������൱���ӵIJ��֣�
���ʱ�����Ҫ�õ����ص�DfSOutputStream����
�ⲿ��̫�����ˣ������ȷ���һЩ����ģ��������ⲿ�ֵ�ʵ�֡�
�����ֲ�ʽ�ļ�ϵͳ������ͨѶ���ַ�Ϊ���ࣺ
1.��������ã��ⲿ��ͨ��HADOOP��RPC���ƽ���֧�֣�
2.��ʽ���ݴ��䣨�ⲿ��ͨ��HADOOP����ʽ���ݴ���Э��֧�֣�
Ϊ�˱�֤���ݵ���ȷ�ԣ�hadoop�ڶ���ؼ�������Ԫ�������ݼ������������ʽ�������紫�䲿��ͨ��У��ͱ�֤���ݴ���������
?
Client��DfSOutputStream�������write����ʱ��ϵͳ���������ϰ�����д��SOCKET�У������������Package������ЩPackage����һ�����С�
��DfSOutputStream����ʱ��ϵͳͨ��Hadoop������RPC���Ƶ���Namenode��create����������һ����̨�߳�?streamer.start();?����̵߳���ҪĿ�ľ��ǽ�������package����д��SOCKET�С�
?
�������ȿ�DfSOutputStream�ļ̳й�ϵ
?
?
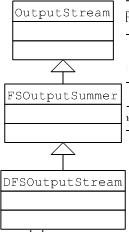
?
����FSOutputSummer�������ʵ����һ��decorator���ģʽ��ʵ�֣���Ҫ��Ŀ�ľ�����OutputStream��void?write(byte?b[],?int?off,?int?len)����������һЩ���ܣ������Ѿ�������ļ����ݴ����ͬʱ��ϵͳ���ڴ�������������Ӽ�������ݣ�ϵͳ�յ����ݺ�����ݽ���У�飬��֤���ݴ������ȷ��,�����û��ڶ��ļ���������в�����ʱ����Ҫ��עУ������ݣ��û�ֻ��Ҫ���ϵĵ���write������Ŀ���ļ��������ݡ�
���ǿ�һ��FSOutputSummer��write(byte?b[],?int?off,?int?len)��ʵ��
public?synchronized?void?write(byte?b[],?int?off,?int?len)
??throws?IOException?
{
????if?(off?<?0?||?len?<?0?||?off?>?b.length?-?len)?{
??????throw?new?ArrayIndexOutOfBoundsException();
????}
for?(int?n=0;n<len;n+=write1(b,?off+n,?len-n))?
{?}
}
���Կ������ϵ���write1��������֤���ݷ��͵������ԡ�
?
��ôwrite1����������ʲô�����أ�write1���û���Ҫд�������������д���Լ���BUFFER�У��ﵽһ��������������һ��chunk�Ĵ�С�������CheckSum�������õõ�һ�����ݵ�У��Ͱ���һ����ʽҪ��һ��д��Stream
private?int?write1(byte?b[],?int?off,?int?len)?throws?IOException?{
if(count==0?&&?len>=buf.length)?
{
??????//?local?buffer?is?empty?and?user?data?has?one?chunk
??????//?checksum?and?output?data
??????final?int?length?=?buf.length;
??????sum.update(b,?off,?length);
??????writeChecksumChunk(b,?off,?length,?false);
??????return?length;
????}
????
????//?copy?user?data?to?local?buffer
????int?bytesToCopy?=?buf.length-count;
????bytesToCopy?=?(len<bytesToCopy)???len?:?bytesToCopy;
????sum.update(b,?off,?bytesToCopy);
????System.arraycopy(b,?off,?buf,?count,?bytesToCopy);
????count?+=?bytesToCopy;
if?(count?==?buf.length)?
{
??????//?local?buffer?is?full
??????flushBuffer();
????}?
????return?bytesToCopy;
?}
?
sum��ʲô�����أ�?new?CRC32()��ͨ���������õ�У���
�Ӵ����п�������Ŀ������û�������outputstream�������ݣ���Щ���ݻ����ȴ浽һ��buffer�У����û�д������ݴﵽһ��������������һ��chunk�Ĵ�С����ͻ���������ȡУ��ͣ�Ȼ��ͨ��writeChecksumChunk��������������Լ��ò������ݵ�У��ͣ�����һ����ʽһ��д�뵽SOCKET��
?
����������һ��һ��writeChecksumChunk()�������
private?void?writeChecksumChunk(byte?b[],?int?off,?int?len,?boolean?keep)?throws?IOException
{
int?tempChecksum?=?(int)?sum.getValue();
if?(!keep)
{
sum.reset();
}
int2byte(tempChecksum,?checksum);
writeChunk(b,?off,?len,?checksum);
}
?
�����������Ҫ���þ��ǽ��û�д��������Լ��ò������ݵ�У�����Ϊ��������writeChunk()���������������һ���鷽����������ʵ����DFSOutputStream������У���Ҳ�������������FSOutputSummer���������ý������������������У������ݣ�������������ν��д������ͨ��DFSOutputStream��ʵ�ֵġ�
��ô��������Ҫ˵���ľ���DFSOutputStream��writeChunk��������ˡ�
?
HDFS��ʽ�������紫��Ļ�����λ����Щ�أ�
chunk->package->block
���������Ѿ���������û�д������ݴﵽһ��������������һ��chunk�Ĵ�С����ͻ���������ȡУ��͡�
һ��������chunk�ͻ����һ��package,���package�������ս������紫��Ļ�����Ԫ��datanode�յ�package����Щpackage����������յõ�һ��block��
?
���ǽ�����ͨ��ʵ����Ҫ�Ĵ����˽��ⲿ�ֹ��ܵ�ʵ�֣�
currentPacket��������ʼ����ʱ�����null,��һ��д������ʱ����жϳ���
if?(currentPacket?==?null)
{
currentPacket?=?new?Packet(packetSize,?chunksPerPacket,
bytesCurBlock);
...
//���濪ʼ����package����
//��package��������һ��chunk�������������chunk���������ݵ�checksum
currentPacket.writeChecksum(checksum,?0,?cklen);
//Ȼ���������chunk������������
currentPacket.writeData(b,?offset,?len);
//�������package��������chunk����
currentPacket.numChunks++;
//��ǰ�Ѿ�д���byte����
bytesCurBlock?+=?len;
?
//?If?packet?is?full,?enqueue?it?for?transmission
//������package�Ѿ��ﵽһ����chunk����,��ʵ�ʵĴ������
if?(currentPacket.numChunks?==?currentPacket.maxChunks
||?bytesCurBlock?==?blockSize)
{
......
//����û�д������ݣ��Ѿ��ﵽһ��blockȱʡ��С��64M��
if?(bytesCurBlock?==?blockSize)
{
//���õ�ǰ��package��ijһ��block�����һ��package
currentPacket.lastPacketInBlock?=?true;
//���һЩ������ֵ
bytesCurBlock?=?0;
lastFlushOffset?=?-1;
}
//�����δ����ǹؼ���һ���ִ��룬���Ѿ�������ɵ�packageд��һ��dataQueue���У�����һ���̣߳��������ǿ�ʼ�ᵽ�ģ�����һ����̨�߳�?streamer.start();?����̵߳���ҪĿ�ľ��ǽ�������package����д��SOCKET�У��Ӹö����в���ȡ��package������ʵ�ʵ����紫��
dataQueue.addLast(currentPacket);
//����event������֪ͨ�����ѵȴ��߳�
dataQueue.notifyAll();
?
//��һ��Ҳ����Ҫ,����currentPacket?Ϊ�գ���ʾ���package�Ѿ����ˣ���Ҫnewһ���µ�package���������û������һ����Ҫд������ݡ�
currentPacket?=?null;
?
//?If?this?was?the?first?write?after?reopening?a?file,?then
//?the?above?write?filled?up?any?partial?chunk.?Tell?the?summer?to?generate?full
//?crc?chunks?from?now?on.
if?(appendChunk)
{
appendChunk?=?false;
resetChecksumChunk(bytesPerChecksum);
}
int?psize?=?Math.min((int)?(blockSize?-?bytesCurBlock),
writePacketSize);
computePacketChunkSize(psize,?bytesPerChecksum);
}
?
computePacketChunkSize�����������Ҫ�����Ǽ�������������
1.chunksPerPacket
��������package��Ҫ���ض��ٸ�chunk;��Ϊ���һ��package���ص�chunk�������ļ���СҲ�й�ϵ��
2.packetSize
��������package�Ĵ�С��
���������������ж��Ƿ���Ҫnewһ���µ�PACKAGE���й�ϵ��
?
private?void?computePacketChunkSize(int?psize,?int?csize)
{
?
int?chunkSize?=?csize?+?checksum.getChecksumSize();
int?n?=?DataNode.PKT_HEADER_LEN?+?SIZE_OF_INTEGER;
chunksPerPacket?=?Math.max((psize?-?n?+?chunkSize?-?1)?/
chunkSize,1);
packetSize?=?n?+?chunkSize?*?chunksPerPacket;
if?(LOG.isDebugEnabled())
��
?
���Կ���������package�������ӵ�dataQueue������У�streamer.start()����̴߳��е���package����ʵ�����紫�������
?
������漰���Ƚϸ��ӵ����紫��Э�鲿�֡�
�����ȿ�һ���ⲿ�ֵ����̣�
1.�����Ѿ�����,��ʼ��һ�����ǿͻ��˵���create��������namenode�ϵ�Ŀ¼����ע��һ��INodeFileUnderConstruction�ڵ�,���õ�һ��DfSOutputStream��
2.�û��õ����outputStream��Ϳ��Խ���д��������û�д������ݾͲ��Ϲ�����packageд��dataQueue������С�
3.streamer.start()����̴߳�dataQueue������ȡ��package����ʵ�����紫�������
��������紫������Ϊ�ؼ����̣�
4.streamer��һ��DataStreamer��ʵ��������һ���߳�ʵ�������֪��HDFS�е��ļ����ݻ�ֳɺܶ�64M��С��block,������HDFS�б����ļ����ݵ�һ��������namenode������һ�������blockID����Ȼ����ͨ��RPC���õķ�ʽ����
?
?

�ļ�д������
?
?
?

�γɵ����ݴ�����·
?
?
?

��·��ijһ�ڵ��ǰ����·
?
DataStreamer�߳�ʵ��������Ҫ�ķ�����
public?void?run()
{
....//���ϴ�����
Packet?one?=?null;
synchronized?(dataQueue)
{
//?process?IO?errors?if?any
boolean?doSleep?=?processDatanodeError(hasError,?false);
//?wait?for?a?packet?to?be?sent.
while?((!closed?&&?!hasError?&&?clientRunning?&&?dataQueue
.size()?==?0)?||?doSleep)
{
try
{
dataQueue.wait(1000);
}
catch?(InterruptedException?e)
{}
doSleep?=?false;
}
if?(closed?||?hasError?||?dataQueue.size()?==?0
||?!clientRunning)
{
continue;
}
try
{
//?get?packet?to?be?sent.
//��dataQueueȡ��package�����з���
one?=?dataQueue.getFirst();
long?offsetInBlock?=?one.offsetInBlock;
?
//?get?new?block?from?namenode.
if?(blockStream?==?null)
{
LOG.debug("Allocating?new?block");
//�����������Ҫ��������Ҫ��ϸ��������Ҫ�IJ���������ͨ��RPC������namenode�������µ�block,�Լ����block�����и�����Ҫ��������Щdatanode�ϣ���Ҫ����һ��LocatedBlock�������������ݴ�����·��
nodes?=?nextBlockOutputStream(src);
this.setName("DataStreamer?for?file?"?+?src
+?"?block?"?+?block);
response?=?new?ResponseProcessor(nodes);
response.start();
}
?
//���û�д������ݰ���У�����Ϣ����ͨ�����������紫����·�����ȥ
blockStream.write(buf.array(),?buf.position(),?buf
.remaining());
//...���´���ʡ��
��
��
��
?
�������������ȿ�һ��LocatedBlock�����ʵ��
public?class?LocatedBlock?implements?Writable?
{
??//...���ϴ���ʡ��
//��namenode��������µ�block
private?Block?b;
?
//���block������ļ���ƫ����
??private?long?offset;?
?
//���block�ĸ�����������Щdatanode�ڵ���
??private?DatanodeInfo[]?locs;
//...���´���ʡ��
��
����LocatedBlock�����ʵ����client�Ϳ�����datanode�ڵ㽨���������ݵ���·���ϴ����block��Ӧ�������ļ����ݡ�
?
�����ļ��ϴ�Э��ϸ�����ǻ���3.2.1�½ڽ�������
?
�����ļ������洢�ĵط�����datanode�����û���Ҫ����ļ���ijһ��block��ʵ����������ʱ������Ҫ���ӵ�datanode����ʵ�ʵ�blockд��������������ǿ�һ��datanode��ι���block���Լ���δ洢block��
Datanode��ͨ���ļ��洢block���ݵģ�datanode����һ��FSDatasetInterface�ӿڣ�����ӿڵ���Ҫ���þ��Ƕ�block��Ӧ��ʵ�������ļ����в�����
�������ǿ�һ���ⲿ���漰����Ҫ���ϵ��
?
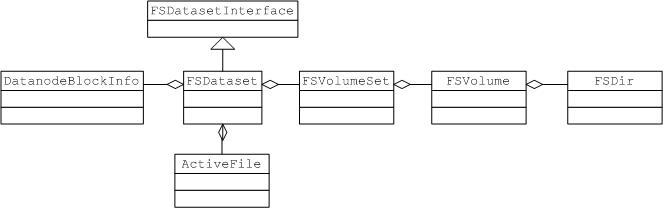
FSDatasetʵ���˽ӿ�FSDatasetInterface����Ҫ����block��Ӧ���ļ�������
FSDataset�м�����Ҫ�����ԣ�
FSVolumeSet?volumes;
private?HashMap<Block,?ActiveFile>?ongoingCreates?=?new?HashMap<Block,?ActiveFile>();
private?HashMap<Block,?DatanodeBlockInfo>?volumeMap?=?null;
?
Datanode�������ö��Ŀ¼���洢block��Ӧ���ļ������õ�ÿһ��Ŀ¼�Ͷ�Ӧһ��FSVolume��ÿһ��FSVolume��Ӧ��Ŀ¼�л���һ��currentĿ¼�����Ŀ¼����ʵ���ļ���ţ�ͬʱϵͳ�������Ŀ¼�����д����ܶ����ļ��У�ÿ���ļ��д�ŵ��ļ������������Ƶģ���ÿ�����ļ��оͻ��Ӧһ��FSDir����
��ô�ȿ�һ��FSVolume��ӦĿ¼���ļ��ṹ��

/data1/dfs/data/���Ŀ¼���������õ�һ���洢block��Ӧ���ļ���Ŀ¼��Ҳ���Ƕ�Ӧһ��FSVolume������currentĿ¼�������������block���ݿ��ļ��ĵط������л���һ��tmpĿ¼�����Ŀ¼��Ҫ��ʱ���һЩ����д���block�����ļ����ɹ�д����ɺ������ʱ�ļ��ͻ��tmpĿ¼�ƶ���currentĿ¼��
��һ�����ǵ������ļ�����
���Կ�������������/data1/dfs/data/Ŀ¼��Ϊ�������ݴ洢Ŀ¼֮һ��
�������ǿ�һ��ʵ�ʵ�/data1/dfs/data/currentĿ¼�»�����Щ���ݣ�
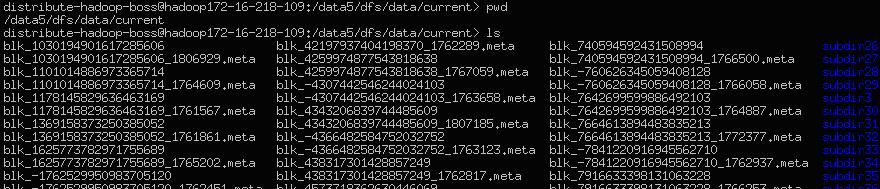
���Կ������Ŀ¼��Ҫ�����block�����ļ���block�����ļ�������������blk_$BLOCKID$,���о���block�ļ���Ԫ�����ļ���Ԫ�����ļ������������ǣ�blk_$BLOCKID$_$ʱ���$,ͬʱ��ҿ��Կ����ܶ�����subdir00�������ļ��У���Щ�ļ������д�ŵ�Ҳ��block�����ļ�����Ԫ�����ļ���hadoop�涨ÿ��Ŀ¼��ŵ�block�����ļ������������Ƶģ��ﵽ����֮��ͻ��½�sub��Ŀ¼���д�ţ���Щsub��Ŀ¼����currentĿ¼�������һ��FSDir�����Ӧ��
��������һ��FSDir�������������ļ�ϵͳ�е�Ŀ¼�Ǻ�����ĸ��������Ҫ���þ��ǹ���һ��Ŀ¼�µ�������block��ص��ļ���
�����ȿ�һ����������Ҫ���ԣ�
//��������Ӧ���ļ�Ŀ¼����
File?dir;
//���Ŀ¼�µ����ļ��ж���
FSDir?children[];
��������ڽ���ʵ��������Ĺ��̾ͻ�����ļ����µ��ļ����ж���Щ��Ŀ¼��Ȼ��������Ӧ��FSDir���ӵ�children�����С�
��Ҫ������
void?getVolumeMap(HashMap<Block,?DatanodeBlockInfo>?volumeMap,
FSVolume?volume)
�����������ҪĿ�ľ��DZ�������Ŀ¼���õ�����block�ļ��б�������������block�ļ�¼��FSDataset��volumeMap�����У������е�volumeMap���������FSDataset��volumeMap���ԣ��������block��DatanodeBlockInfo��ӳ���ϵ������ͨ��block��ѯ�����block�ļ���Ϣ��
datanodeBlockInfo������Ҫ������block������һ��FSVolume���Լ�block��ʵ�ʵĴ���ļ����ĸ���
?
{
if?(children?!=?null)
{
for?(int?i?=?0;?i?<?children.length;?i++)
{
//�������ļ���
children[i].getVolumeMap(volumeMap,?volume);
}
}
?
File?blockFiles[]?=?dir.listFiles();
for?(int?i?=?0;?i?<?blockFiles.length;?i++)
{
//�ж��ļ��Ƿ���һ��block����Ҫ��ͨ���ļ������жϵģ�block���ļ���������������"blk_$BLOCKID"
if?(Block.isBlockFilename(blockFiles[i]))
{
long?genStamp?=?getGenerationStampFromFile(blockFiles,
blockFiles[i]);
volumeMap.put(new?Block(blockFiles[i],?blockFiles[i]
.length(),?genStamp),?new?DatanodeBlockInfo(volume,blockFiles[i]));
}
}
}
?
Volumes�����˵�Ƚϼ�������һ��FSVolume����,����װ�˶�����volume�IJ��������磺getBlockReport()������������ǵõ����е�block�б����ϱ���namenode������volumes������϶������������IJ����Ϳ��Է�װ�������������������
?
ongoingCreates?
���������Ҫ�洢�����ڴ�����block�б�����������е�block��ʾ�û����ڽ��и�block�ļ������ϴ���������������а���ActiveFile�����ʵ���������ȿ�һ��ActiveFile��������������������ؼ����ԣ�1.�����Ӧ�������ļ���2.���ڲ�������ļ����߳��б���
final?File?file;
final?List<Thread>?threads?=?new?ArrayList<Thread>(2);
�����߳��б�����ҪĿ���ǣ�
�ڽ���block�ļ�д�����ʱ�����datanode�յ��˶����block����recoverblock���������Ҫ��interrupt��������д�����block�ļ����̡߳�
?
�����ȿ�һ���ļ����ݵĽ������̡�
�ڽ�������3.2.2�½����ǻ���ϸ����datanode�������ݵ�Э�飬�����л��ᵽDatanode����һ��BlockReceiverʵ��������ʵ�����ݵĽ��ܲ�����
?
BlockReceiver�ڹ���ʵ�������л�����ͨ�����·�����streams?=?datanode.data.writeToBlock(block,?isRecovery);��block����д��datanode�����ļ���ͨ�����Ա�datanode���յ�block���ݿ�������Ժ���������д����̡���һ�����ǿ�����Ҫ�˽�BlockWriteStreams���������ΪwriteToBlock�᷵��BlockWriteStreams����ʵ����
static?class?BlockWriteStreams?
{
??????OutputStream?dataOut;
??????OutputStream?checksumOut;
??????BlockWriteStreams(OutputStream?dOut,?OutputStream?cOut)?{
????????dataOut?=?dOut;
????????checksumOut?=?cOut;
}
���ǿ��Կ�������������������Ҫ�����ԣ�dataOut��checksumOut����������˼����Ҳ���Դ����������outputstream����һ������д��block���ݣ�һ������д��block�����е�checksum���ݡ�
?
������������ϸ����һ���������:
public?BlockWriteStreams?writeToBlock(Block?b,?boolean?isRecovery)
{
...
//ǰ����Ҫ��һЩ�Ϸ����жϡ�
...
if?(!isRecovery)
{
v?=?volumes.getNextVolume(blockSize);
//���Ǻ���Ҫ�ķ�������Ҫ���ȴ���һ����ʱ�ļ��洢�ϴ������ݣ���һ����ɵ�block�ļ�д������Ժ��ٽ�����ļ��Լ�Ԫ�����ļ��ƶ�����ʽ�ļ�Ŀ¼��
f?=?createTmpFile(v,?b);
volumeMap.put(b,?new?DatanodeBlockInfo(v));
...
}
...
return?createBlockWriteStreams(f,?metafile);
��
��Ҫ�Ǵ���һ����ʱ�ļ���һ�����Ԫ������Ϣ����ʱ�ļ���Ȼ��������ļ������ص�OutputStream���ظ�ǰ�ˡ�
?
�ļ���ȡ����ļ�д��Ҫ�Ķ�ö࣬client������Ҫ��namenode�õ�һ���ļ���block�б��Լ�ÿ��block��һ���������ڵ�datanode�����client�������Щdatanode�������ӷ��Ͷ�ȡblock���ݵ������̱Ƚϼ����ǿ�һ���ⲿ���漰����Ҫ����
�������ļ���ȡ���ֵ�ǰ�벿�����̣���Ҫ�Ǵ�namenode�ϵõ��ļ���Ӧblock����Ϣ��
?
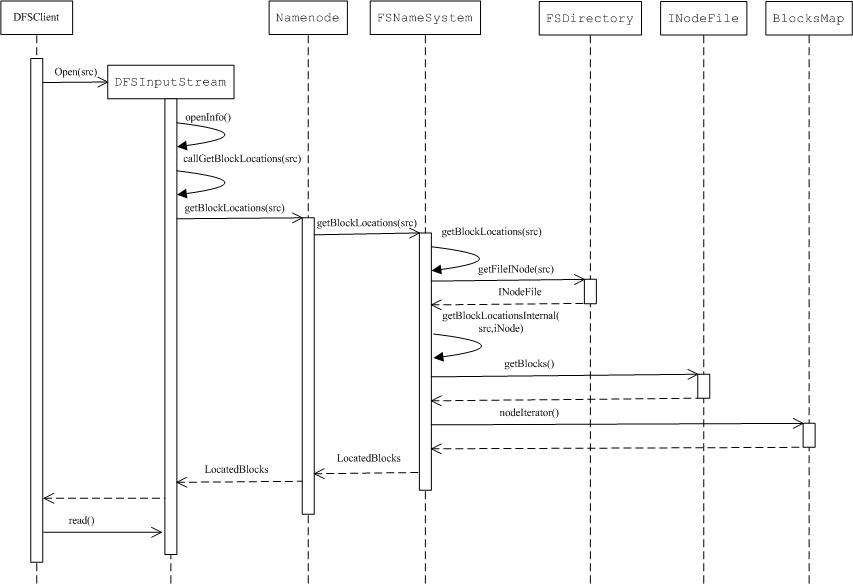
���Կ�����Ҫ�Ƿ���һ��LocateBlocksʵ����DFSInputStream����LocateBlocks������Ҫ��������ʲô�أ��������ȿ�һ���������Ļ������ԣ�
public?class?LocatedBlocks?implements?Writable
{
private?long?fileLength;
private?List<LocatedBlock>?blocks;
...
}
���Կ��������������Ҫ�����Ծ���List<LocatedBlock>?blocks��һ���ļ������ֶΣ�LocatedBlock�����Ѿ������ἰ������LocatedBlock�����ʵ����client�Ϳ�����datanode�ڵ㽨���������ݵ���·����ȡ���block��Ӧ�������ļ����ݡ�
?
�������ǿ�һ��block���ݵĶ�ȡ���̣��϶���datanode�й�����,���漰���ļ���ȡ���������Э�飬Э�鲿�ֿ��Բο�3.2.3�½ڡ�
?
�������ǿ�һ���ļ���ȡ�����漰������Ҫ����
DFSClientһ����ض���
?
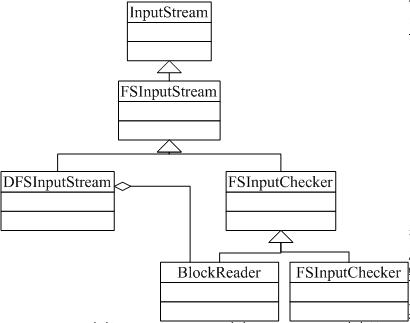
InputStream��JDK�еĻ������ij�����࣬FSInputStream��Ҫ�����������鷽���Ķ��壺
public?abstract?void?seek(long?pos)?throws?IOException;
public?abstract?long?getPos()?throws?IOException;
public?abstract?boolean?seekToNewSource(long?targetPos)?throws?IOException;
������ĵ�������ͼ�п��������Ŀ�����DFSClient�����ȹ���һ��DFSInputStreamʵ������DFSInputStream��������л��������openInfo����������ɻ����ij�ʼ����������Ҫ�Ǵ�Namenodeͨ��RPC���õõ��ļ���block�б���Ϣ����Ӧ��LocatedBlocks��һ������ʵ����
���������ǾͿ�һ��DFSInputStream���read��������ȡ���ݵIJ�����Ҫ�����ڴ�namenode���ص�LocatedBlocksʵ����
public?synchronized?int?read(byte?buf[],?int?off,?int?len)
throws?IOException
{
...
//������һЩ��鹤��
...
if?(pos?<?getFileLength())
{
int?retries?=?2;
while?(retries?>?0)
{
try
{
//�������Ƿdz���Ҫ�IJ��裬�ж����ڶ�ȡ��λ���Ƿ��Ѿ�����Ŀǰ���ڲ�����block���ݿ���Ľ���λ�ã�����Ѿ������һ��block���ݿ���Ķ�ȡ����������Ҫ���¶�λ����һ��block����Ҫ����һ��block���ڵ�datanode�������ӣ����Ͷ�ȡ���ݵ�����
if?(pos?>?blockEnd)
{
currentNode?=?blockSeekTo(pos);
}
int?realLen?=?Math.min(len,?(int)?(blockEnd?-?pos?+?1));
//��ʼ����datanode������SOCKET�����ж�ȡ���ݡ�
int?result?=?readBuffer(buf,?off,?realLen);
?
if?(result?>=?0)
{
pos?+=?result;
}
...
}
}
}
}
?
���Կ���read()�����е�����һ������Ҫ�ķ���������blockSeekTo(pos),���ǿ�һ�����������ʵ�֣�
?
private?synchronized?DatanodeInfo?blockSeekTo(long?target)
throws?IOException
{
...
//blockReader��һ����װ�Ķ�����Ҫ���þ��Ǵ�datanode��ȡblock��ʵ�����ݣ����������ٽ�
if?(blockReader?!=?null)
{
//�ر���ԭ��datanode�����ӣ���Ϊ��һ��block�Ѿ���ȡ�����
blockReader.close();
blockReader?=?null;
}
if?(s?!=?null)
{
//�ر���ԭ��datanode�����ӣ���Ϊ��һ��block�Ѿ���ȡ�����
s.close();
s?=?null;
}
//����������Ǵ�LocatedBlocks���������LocatedBlock�б��еõ���һ��LocatedBlock��
LocatedBlock?targetBlock?=?getBlockAt(target);
//��һ��block��ȡ��ƫ���������Ӧ����Ҫ�������漴��ȡ����Ҫ��
long?offsetIntoBlock?=?target?-?targetBlock.getStartOffset();
//��λ����ȷ��block,���ǻ���Ҫ��һ�����ʵ�datanode���ж�ȡ����Ϊÿ��block���ж�������ֱ�����ڶ�̨�����ϡ�
DatanodeInfo?chosenNode?=?null;
while?(s?==?null)
{
//ѡ��һ������ʵ�datanode
DNAddrPair?retval?=?chooseDataNode(targetBlock);
chosenNode?=?retval.info;
InetSocketAddress?targetAddr?=?retval.addr;
//�������ݶ�ȡЭ���ֶε�Datanode������ʵ�����ݶ�ȡ����������Э��������3.2.3�½ڽ�����ϸ������
try
{
s?=?socketFactory.createSocket();
s.connect(targetAddr,?socketTimeout);
s.setSoTimeout(socketTimeout);
Block?blk?=?targetBlock.getBlock();
//����һ��blockreader������ʵ��block���ݿ�Ķ�ȡ
blockReader?=?BlockReader.newBlockReader(s,?src,?blk
.getBlockId(),?blk.getGenerationStamp(),
offsetIntoBlock,?blk.getNumBytes()
-?offsetIntoBlock,?buffersize,
verifyChecksum,?clientName);
return?chosenNode;
}
}
}
?
DFSInputStream�ڹ����ʱ��������������openInfo()������namenode�õ�һ��LocatedBlocks������������ȡ�ļ���LocatedBlock�б���getBlockAt()���������LocatedBlock�б��еõ���һ��Item,hadoop��namenode����һ���ļ���block��Ϣʱ��������һ����ȡ������block��Ӧ��LocatedBlock��
callGetBlockLocations(namenode,?src,?offset,prefetchSize);
�����е�prefetchSize����������ÿ��Ԥȡһ��������block��Ϣ���ȶ�ȡ��ɺ���ȡ��һ����
?
�����Ҫ����һ��BlockReader��������ˣ�
blockReader?=?BlockReader.newBlockReader(s,?src,?blk.getBlockId(),?blk.getGenerationStamp(),offsetIntoBlock,?blk.getNumBytes()-?offsetIntoBlock,?buffersize,verifyChecksum,?clientName);
?
������������������������Ҫ��������blockReader�������ݶ�ȡ
//��ʼ����datanode������SOCKET�����ж�ȡ���ݡ�
int?result?=?readBuffer(buf,?off,?realLen);
?
blockReader�̳���FSInputChecker��FSInputChecker����ҪĿ�ľ��ǶԴ�datanode��ȡ�����ݽ���checksum��У�������������������ᵽ��д��block���ݵ�ʵ�ַ�ʽ���һ�ޣ�FSInputChecker��ʵ��һ��Decorator��ʵ�ַ�ʽ�������ݶ�ȡ�Ĺ����в���������У��Ĺ��ܡ�
?
private?synchronized?int?readBuffer(byte?buf[],?int?off,?int?len)
throws?IOException
{
IOException?ioe;
boolean?retryCurrentNode?=?true;
while?(true)
{
try
{
return?blockReader.read(buf,?off,?len);
}
....
boolean?sourceFound?=?false;
//�����һ��Datanode���Զ�ζ�ȡʧ���Ժ���Ҫ��������Datanode�Ͻ��ж�ȡ��
if?(retryCurrentNode)
{
sourceFound?=?seekToBlockSource(pos);
}
else
{
addToDeadNodes(currentNode);
sourceFound?=?seekToNewSource(pos);
}
retryCurrentNode?=?false;
��
��
?
���������ǿ�һ��blockReader.read()������ʵ�֡�
?
public?synchronized?int?read(byte[]?buf,?int?off,?int?len)
throws?IOException
{
//�û��ܿ��ܲ��Ǵ��ļ�ͷ�����ļ����ж�ȡ����������ڶ�λ���ĵ�һ��blockҲӦ���Ǻܿ�����ƫ�Ƶģ����о����ڶ�ȡblock�Ĺ����г�����,ȥ��һ��datanode��ȡ��blockʣ�µ����ݡ�
if?(lastChunkLen?<?0?&&?startOffset?>?firstChunkOffset?&&?len?>?0)
{
int?toSkip?=?(int)?(startOffset?-?firstChunkOffset);
if?(skipBuf?==?null)
{
skipBuf?=?new?byte[bytesPerChecksum];
}
//����FSInputChecker��read��������������ĵ�����Ҫ�ǶԴ�datanode��ȡ���������ݽ���У��Ͳ���
if?(super.read(skipBuf,?0,?toSkip)?!=?toSkip)
{
throw?new?IOException(
"Could?not?skip?required?number?of?bytes");
}
}
?
boolean?eosBefore?=?gotEOS;
int?nRead?=?super.read(buf,?off,?len);
}
?
?
�������ǾͿ�һ��FSInputChecker.read()������ʵ��
public?synchronized?int?read(byte[]?b,?int?off,?int?len)?throws?IOException
{
...//һЩ������鹤��
int?n?=?0;
for?(;;)
{
int?nread?=?read1(b,?off?+?n,?len?-?n);
if?(nread?<=?0)
return?(n?==?0)???nread?:?n;
n?+=?nread;
if?(n?>=?len)
return?n;
}
��
?
���Ĺ��ܻ�����read1()������ʵ��
?
private?int?read1(byte?b[],?int?off,?int?len)?throws?IOException
{
int?avail?=?count?-?pos;
if?(avail?<=?0)
{
//����û��Լ��ṩ��buffer�㹻�洢��ȡ�����ݣ���ֱ��д���û���buffer��
if?(len?>=?buf.length)
{
//�������������ж�ȡһ��chunk��λ�����ݣ�������checksum��֤
int?nread?=?readChecksumChunk(b,?off,?len);
return?nread;
}
else
{
//����д��ϵͳBUFFER�У���ɺ����û��ṩ��buffer�С�
fill();
if?(count?<=?0)
{
return?-1;
}
else
{
avail?=?count;
}
}
}
int?cnt?=?(avail?<?len)???avail?:?len;
System.arraycopy(buf,?pos,?b,?off,?cnt);
pos?+=?cnt;
return?cnt;
��
?
readChecksumChunk�����readChunk�������������������Ҫ��ʵ����BlockReader�����У�FSInputCheckerĿ�Ľ����ǶԶ�ȡ�����ݺ���Ӧ��У�����ݽ���У�飬BlockReader����ʵ�����ݶ�ȡ��������Ҫ���Ǹ���hadoop����������Э������ݽ��н���;
?
FileSystem��һ���ṩ���û����ļ�ϵͳ���з��ʵij����࣬����HDFS�ľ���ʵ����ΪDistributedFileSystem,�û���HDFS�����в�������ͨ�������ľ���ʵ����ɵġ���HDFSд���ļ�֮ǰ��Ҫ������Namenode������ע��һ��INodeFileUnderConstruction�������ļ�����������ʱ���������һ�ļ������ϵͳ����BLOCK������ǵ�һ��д�루������һ��BLOCK�Ѿ�д��������Ҫ��Namenode��ע��һ���µ�BLOCK��ͨ��RPC����Namenode�ľ���ʵ������LocatedBlock�������������block���LocatedBlock���������datanodeinfo��Ϣ����ʾ���block�����Ҫ�������Щdatanode�Ͻ��б��档
����������ϸ��һ�����ݴ���ľ��������Լ�����Э�����ϸ���ݣ�
��һ�������صĶ��datanode������������γ����ݴ�����������ͼ��ʾ�����������ݿ���Ϊ������
?
?
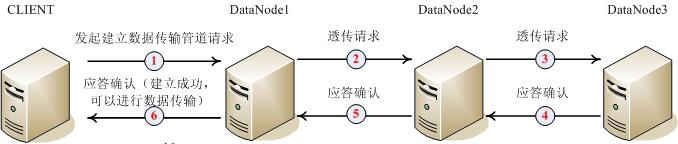
�����̵����6����ʱ������ܵ����㽨���ɹ���ÿһ����������һ���ڵ㽨�����ӣ����ܵ�����Э�����
�������ǿ�һ�¹ܵ�����Э�飺
?
4�ֽ�
���ݴ���Э��汾�ţ�0.19.1�汾��hadoop����ֶ�Ϊ14��
4�ֽ�
�����루���ļ�ʱΪ��OP_WRITE_BLOCK��
8�ֽ�
Block��BLOCKID�ֶ�
8�ֽ�
Block��ʱ����ֶ�
4�ֽ�
�����Ĵ�������һ���ж���̨datanode
boolean
��ʾ�Ƿ�Ϊ�ָ���������recoverblock������
Text
Client�����ִ�����ʽΪ�ִ����ȣ������ȡ��ѹ����ʽ��+�ִ�����
boolean
��ʾ�Ƿ���ͻ�����Ϣ
DatanodeInfo
��������ֶ�Ϊtrue���Ż��и��ֶΣ���ʾclient��Ϣ
int
��ʾ�������к����ڵ������ÿ��һ���ڵ㣬����ֶξͼ���һ��
DatanodeInfo[]
��ʾ�������к����ڵ���Ϣ�������ֽ��Ƕ��پͶ����ٸ�DatanodeInfo��Ϣ����������Ľڵ�����һ�ڵ������
Checksum
byte
Checksum�����ͣ����Ը��ݸ��ֶ�ʵ��������checksum��
int
�Զ����ֽڽ���ȡchecksum����
?
?
?
Client��������������͵ȴ�Ӧ��Ӧ���Э���ʽ���£�
?
Text
Client�����ִ�����ʽΪ�ִ����ȣ������ȡ��ѹ����ʽ��+�ִ�����
?
���ؾ���һ���ִ���Ϣ������ִ�Ϊ�ձ�ʾ�����ڵ�������·�����ӳɹ��������Ϊ�ո��ֶα���ľ��dz�����datanode��Ϣ����ʽ���£�name:port��
?
�����һ��block�����������������·�ɹ��ԺͿ��Խ���ʵ�����ݴ����ˡ���������ݾ���һ����һ����Package����
?
4�ֽ�
Package���ݳ���
4�ֽ�
package�����block�е�ƫ����
8�ֽ�
һ�����к�
byte
���package�Ƿ������block�����һ����
4�ֽ�
ʵ�ʵ����ݳ��ȣ���ȥchecksum��
CheckSum����
ȱʡ��CheckSumΪCRC32����ȱʡÿ��chunk��checksumռ�ĸ��ֽڣ�
ʵ��block����
������
?
?
���ݴ��������һ����Ҫ��ʱ�����֪�����ݴ������е�datanode���������������أ��Լ�datanode�ɹ��յ�package���Ժ������Ӧ�����ⲿ��Э������ֶ����£�
����յ���һ��datanode����4�ֽڣ�-1������ʾ��������
?
4�ֽ�
opCode(-1,��ʾ��������)
?
?
����յ���һ��datanode����4�ֽڣ�������-1��Ҳ������-2��
?
4�ֽ�
packageID(����һ�����ؽ��ܵ���packageID)
4�ֽ�
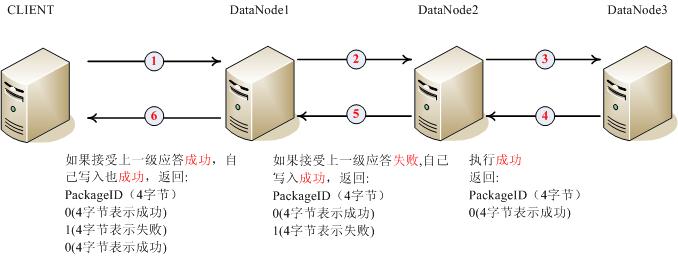
?client���տ��Ը��ݷ��ص�PackageID��Ķ��״̬�ֽڵ�֪��̨�������ܳ������⣬����������̿��Կ�����datanode3�����Ѿ�д��ɹ���datanode2����û���յ�datanode3��Ӧ�𣬹ʶ���Ϊdatanode3����packageʧ�ܣ����״̬һֱ����client��
Ҳ�п���datanode3�ڵ��ȷʧЧ��datanode2Ҳ���ղ���datanode3��Ӧ����Ӧ��
������������ϸ����һ�����ģ�����Ҫ�漰����ģ�����
?
DFSClient��Namenodeȡ����Ҫ��ȡ���ļ���Ӧ��LocatedBlocks��Ϣ�Ժͻᰴ��block��˳����datanode�������Ӳ����Ͷ�ȡblock���ݵ��������ǿ�һ���ⲿ�ֵ�Э���ʽ��
?
4�ֽ�
���ݴ���Э��汾�ţ�0.19.1�汾��hadoop����ֶ�Ϊ14��
4�ֽ�
�����루��ȡ�ļ�ʱΪ��OP_READ_BLOCK,��Ӧ81��
8�ֽ�
Block��BLOCKID�ֶ�
8�ֽ�
Block��ʱ����ֶ�
8�ֽ�
��ȡ��block�����ļ���ʼ��ƫ����
8�ֽ�
һ����ȡ�����ֽ�
Text
Client�����ִ�����ʽΪ�ִ����ȣ������ȡ��ѹ����ʽ��+�ִ�����
?
?
DFSClient���Ͷ�ȡ���ݿ����������Ժ����ȵȴ�datanode��Ӧ��datanodeӦ��Э���ʽ���£�
?
?
4�ֽ�
OP_STATUS_SUCCESS=0��ʾ���ӽ����ɹ�OP_STATUS_ERROR=1��ʾ���ӽ���ʧ��
?
?
?
������Datanode�Ϳ�ʼ�������ݴ��ͣ��������ݸ�ʽ���£�
?
����У�������Ϣ
Byte
Chunksum����
int
bytesPerChecksumÿ��checksum��Ӧ���ֽ���
8�ֽ�
����8�ֽ���Щ�����û�еģ�
Offset����ȡһ��block��ʼ��ƫ������
1.DFSClient��Datanode��ȡblock����ʱ������ֶ��DZ����еġ�
2.Datanode֮�����block�����ʱ��balance��Ҫ������block���û�дﵽ��������Ҫ������ֶ��Dz����ڵġ�
4�ֽ�
packetLen,package����
8�ֽ�
chunk��ƫ�������Ñ���ȡ�ļ�ʱ���ܿ���ƫ��һ��λ�ã�ƫ�Ƶ�λ�úܿ��ܲ���һ��chunk�Ľ���λ�ã���Ϊchecksum�ǰ���chunk������ģ�����hadoop�Ὣ�ⲿ��ƫ���������ݶഫ��client��client��Ҫ���ⲿ�����ݶ�����
8�ֽ�
Seqno���к�
byte
�Ƿ���block���ݿ�����һ��package
4�ֽ�
�����block�а��������ݴ�С
CheckSum����
ȱʡ��CheckSumΪCRC32����ȱʡÿ��chunk��checksumռ�ĸ��ֽڣ�
ʵ��block����
������
?
��3.1.9�½��������Ѿ���ϸ������Client����Ҫ�ϴ��ļ�ʱ����Ҫ���еIJ����Լ����ʵ��ģ�飬��һ�½��������ؽ���datanodeһ��֧�����ݴ������Ҫģ�顣
DataXceiverServer��
datanode�������Ժ�����ȳ�ʼ��һ��DataXceiverServer����ʵ�������������ʵ����Runnable�ӿڵĶ�����������һ���ض��̼߳������ض��˿ڡ�
public?void?run()
{
while?(datanode.shouldRun)?
{
??????try?
?��
???????Socket?s?=?ss.accept();
????????s.setTcpNoDelay(true);
????????new?Daemon(datanode.threadGroup,?
????????????new?DataXceiver(s,?datanode,?this)).start();
?????...
??}}}
���ϴ�����Ǹ��̶߳������Ҫ����ʵ�壬�������Ǽ����˿ڴ��������������������Ժͻᴴ����һ���̴߳��������ӵ�����,����̵߳�����ʵ��ΪDataXceiver��ʵ���������������ص㿴һ��DataXceiver��ʵ�֡�
DataXceiverҲ��ʵ����Runnable�ӿڵ��࣬��Ҫ����run���������С�
?
public?void?run()?
{
????DataInputStream?in=null;?
????try?{
??????in?=?new?DataInputStream(
??????????new?BufferedInputStream(NetUtils.getInputStream(s),?
??????????????????????????????????SMALL_BUFFER_SIZE));
??????//���ȶ�ȡЭ��汾�ţ��������ж�
short?version?=?in.readShort();
??????if?(?version?!=?DataTransferProtocol.DATA_TRANSFER_VERSION?)??{
????????throw?new?IOException(?"Version?Mismatch"?);
??????}
??????boolean?local?=?
s.getInetAddress().equals(s.getLocalAddress());
??????//��ȡ�����룬���ļ�ʱ��Ӧ����OP_WRITE_BLOCK
??byte?op?=?in.readByte();
??????...
??????}
??//ͨ���û��������IJ����룬������Ӧ�IJ���
??????long?startTime?=?DataNode.now();
??????switch?(?op?)
?{
??????case?DataTransferProtocol.OP_READ_BLOCK:
????????readBlock(?in?);
????????datanode.myMetrics.readBlockOp.inc(DataNode.now()?-?startTime);
????????if?(local)
??????????datanode.myMetrics.readsFromLocalClient.inc();
????????else
??????????datanode.myMetrics.readsFromRemoteClient.inc();
????????break;
??????case?DataTransferProtocol.OP_WRITE_BLOCK:
????????writeBlock(?in?);
????????datanode.myMetrics.writeBlockOp.inc(DataNode.now()?-?startTime);
?
????????...//ʡ��
?
??????default:
????????throw?new?IOException("Unknown?opcode?"?+?op?+?"?in?data?stream");
??????}
????}?
...
ǰ������һֱ�������ļ�д���ʵ�֣����Ǿ����ȿ�һ��writeBlock(?in?);������Ҫ�漰���ļ�block����Э��ؼ��ֶεĶ�ȡ��������ݴ�����·�Ľ����Լ�block���ݿ���Ĵ��䡣
?
private?void?writeBlock(DataInputStream?in)?throws?IOException
{
DatanodeInfo?srcDataNode?=?null;
//��ȡclient��������blockID��ʱ���������һ��block��
Block?block?=?new?Block(in.readLong(),
dataXceiverServer.estimateBlockSize,?in.readLong());
//���ݴ�����·���ж���̨����
int?pipelineSize?=?in.readInt();?
//�Ƿ���һ������BLOCK�ָ�����
boolean?isRecovery?=?in.readBoolean();?
//�ͻ�������
String?client?=?Text.readString(in);?
//�ͻ����Ƿ��Ǽ�Ⱥ��һ̨datanode����
boolean?hasSrcDataNode?=?in.readBoolean();?
//����ͻ����Ǽ�Ⱥ��һ̨datanode�������õ�datanodeinfo��Ϣ
if?(hasSrcDataNode)
{
srcDataNode?=?new?DatanodeInfo();
srcDataNode.readFields(in);
}
//��ʾ�������к����ڵ������ÿ��һ���ڵ㣬����ֶξͼ���һ��
int?numTargets?=?in.readInt();
?
...
//��ȡ�����ڵ����ϸdatanodeinfo��Ϣ
DatanodeInfo?targets[]?=?new?DatanodeInfo[numTargets];
for?(int?i?=?0;?i?<?targets.length;?i++)
{
DatanodeInfo?tmp?=?new?DatanodeInfo();
tmp.readFields(in);
targets[i]?=?tmp;
}
//����һ��BlockReceiverʵ�����տͻ��˴���������ļ��������ݡ�
blockReceiver?=?new?BlockReceiver(block,?in,?s
.getRemoteSocketAddress().toString(),?s
.getLocalSocketAddress().toString(),?isRecovery,??client,srcDataNode,?datanode);
?
//������Ǹ������淵�ص�datanode�б����������ݴ�����·
mirrorOut.writeShort(DataTransferProtocol.DATA_TRANSFER_VERSION);mirrorOut.write(DataTransferProtocol.OP_WRITE_BLOCK);
mirrorOut.writeLong(block.getBlockId());
mirrorOut.writeLong(block.getGenerationStamp());
mirrorOut.writeInt(pipelineSize);
mirrorOut.writeBoolean(isRecovery);
Text.writeString(mirrorOut,?client);
mirrorOut.writeBoolean(hasSrcDataNode);
if?(hasSrcDataNode)
{?//?pass?src?node?information
srcDataNode.write(mirrorOut);
}
mirrorOut.writeInt(targets.length?-?1);
for?(int?i?=?1;?i?<?targets.length;?i++)
{
targets[i].write(mirrorOut);
}
?
blockReceiver.writeChecksumHeader(mirrorOut);
mirrorOut.flush();
?
?
//�����꽨�����ݴ�����������ȴ���һ���ڵ��Ӧ�𣬷��ؿ��ִ���ʾ��·�����ɹ���
��·�����ɹ��Ժ�Ӧ���ǰһ���ڵ㣬Ȼ����ǵȴ�ǰһ���ڵ㷢���������ݣ���Ҫ��ʵ��������ķ�����
blockReceiver.receiveBlock(mirrorOut,?mirrorIn,?replyOut,
mirrorAddr,?null,?targets.length);
?
�÷����л��ʼ��һ��PacketResponder�̣߳�����̵߳���ҪĿ�ľ��Ƿ�������������һ���ڵ㣬ͬʱ������һ���ڵ�ɹ��յ�pachage���Ӧ�𣬲�����Ӧ����Ϣ��ǰһ���ڵ㣬���������һ��������block������������Ҫ�IJ���Ҫ����
1.datanode.data.finalizeBlock(block);(�ⲿ�����Ǻ����ٽ�����Ҫ����datanode�����block�ļ���tmpĿ¼�ƶ�����ʽ�����ݴ��Ŀ¼)
2.datanode.notifyNamenodeReceivedBlock(block,DataNode.EMPTY_DEL_HINT);����������Ƚϼ���ͬʱnamenode�Լ��յ�һ��block��namenode�Ϳ�����blockinfo�м������datanodeinfo����Ϣ��
?
ͬʱ������������Ҫ��һ��������receivePacket������
����������Ǹ�������������Э�飬����package���ݰ������û������������ӵ�block�ļ��У���Ȼ���кܶ�����У��IJ�����block�ͱ����ļ�����һ��ӳ���ϵ���ⲿ�����Ǻ�����ܣ�����������бȽ���Ҫ�ķ�������readNextPacket(),��Ҫ�Ƕ�ByteBuffer�����������Ӧ�ã���ϸ���Բο����룩��
�ɹ��������һ��Package��ͻ���һ���Ƚ���Ҫ�IJ������ǣ�
((PacketResponder)?responder.getRunnable()).enqueue(seqno,
lastPacketInBlock);
�����յ���package�е�seqno����һ��package����д��һ��ackQueue���У�ǰ���ᵽ��PacketResponder�̴߳Ӹö�����ȡ��seqnoӦ������һ���ڵ㡣
�������ǿ�һ��PacketResponder�̵߳���Ҫ���̣�
?
?
?
?
?

�������ǹ�ͬ����һ��readBlock(?in?)������ʵ�֣����������ҪӦ����DFSClient��ȡblock���ݿ�IJ�������ǰ���Э���ֶ���ϸ�������Ѿ��Ƚ������ؿ������ͻ�����datanode���������Ժ�汾����֤ͨ��������һ��Э���ֶξ���opCode��datanodeͨ�������������к���IJ����������OP_READ_BLOCK(81)��ʾDFSClient��Ҫ����block���ݿ��ȡ����,������ϸ����һ�����������
?
private?void?readBlock(DataInputStream?in)?throws?IOException
{
//����Э�����blockid�ֶ�
long?blockId?=?in.readLong();
//�ٽ���ʱ����ֶι�����block����
Block?block?=?new?Block(blockId,?0,?in.readLong());
//��ȡblockʱ��ƫ��������Щʱ���һ��datanode��ȡblock�����У�datanode���������ʱ�����һ��datanode������ȡ��block��Ҫ��һ��ƫ������
long?startOffset?=?in.readLong();
//��Ҫ��ȡ�����ֽ�
long?length?=?in.readLong();
String?clientName?=?Text.readString(in);
?
OutputStream?baseStream?=?NetUtils.getOutputStream(s,
datanode.socketWriteTimeout);
DataOutputStream?out?=?new?DataOutputStream(
new?BufferedOutputStream(baseStream,?SMALL_BUFFER_SIZE));
?
BlockSender?blockSender?=?null;
try
{
try
{
//blockSender����������block���ݴ�����
blockSender?=?new?BlockSender(block,?startOffset,??length,?true,true,?false,?datanode,?clientTraceFmt);
}
out.writeShort(DataTransferProtocol.OP_STATUS_SUCCESS);?
//��ȡblock���ݰ���Э�����д��out��������
long?read?=?blockSender.sendBlock(out,?baseStream,?null);
...
}
}
���ǿ���blockSender�ڹ���Ĺ����о���������Щ������
{
this.blockLength?=?datanode.data.getLength(block);
...
try
{
if?(!corruptChecksumOk?||
?datanode.data.metaFileExists(block))
{
//��block��Ԫ�����ļ��ж�ȡ��Ϣ����Ҫ��checksum�����Լ�ÿ����checksum���ֽ���
checksumIn=new?DataInputStream(new
BufferedInputStream(datanode.data.getMetaDataInputStream(block)?,BUFFER_SIZE));
BlockMetadataHeader?header?=?BlockMetadataHeader
.readHeader(checksumIn);
short?version?=?header.getVersion();
...
checksum?=?header.getChecksum();
}
else
{
//���û�ж���Ԫ������Ϣ��ʹ��ȱʡ��checksum����
checksum?=?DataChecksum.newDataChecksum(
DataChecksum.CHECKSUM_NULL,?16?*?1024);
}
...
checksumSize?=?checksum.getChecksumSize();
...
?
//?���ݶ�ȡblock��ƫ��λ��ȷ��ƫ��checksum��������λ��
if?(offset?>?0)
{
long?checksumSkip?=?(offset?/?bytesPerChecksum)?*?checksumSize;
if?(checksumSkip?>?0)
{
IOUtils.skipFully(checksumIn,?checksumSkip);
}
}
seqno?=?0;
//���block���ݵĶ�ȡ��������datanode.data����������FSDataset�����ʵ��������block�����ݷ����̾��Ǵ���������ж�ȡblock����
blockIn?=?datanode.data.getBlockInputStream(block,?offset);?
...
}